基于深度学习的个性化音乐推荐算法研究
王晓燕
(集宁师范学院,内蒙古 乌兰察布 012000)
现阶段,个性化推荐已经获得广泛认可,同时充分融入民众生活。音乐是一种人们喜闻乐见的艺术形式,可以给民众带来娱乐,然而在海量音乐中准确寻找符合用户要求的作品,需要通过个性化推荐算法结合用户行为进行有效筛选,满足用户基于当时情景的要求,进而实现众口可调目标[1]。
1.1 Apriori算法
设定音乐项目集合为M={M1,M2,M3,…,Mn},D(字段集合)为项集,子集T为{t1,t2,t3,…,tn},ti⊂I对各个事务标注为Tid,D中项目数量是k。
T在D中出现次数在D中的比重为T支持度,见下式:

支持度代表规则之中事务出现频率,一般会设定最小阈值支持度,如果项集支持度比阈值大,那么变成频繁项集。
设定M1∩M2=∅,那么称D中涵盖T1、T2,T2是项集置信度,见下式:
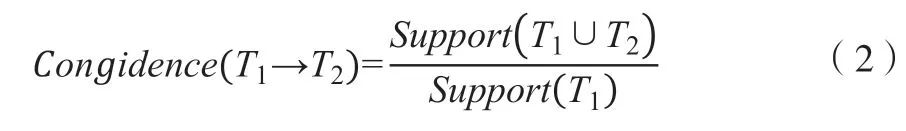
D事务矩阵如下:
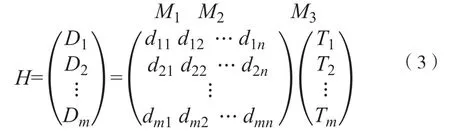
进行计算时,扫描D过程中,若是支持度与置信度均比各自阈值大,则是强关联规则[2]。
在运用Apriori算法开展关联规则计算工作时,主要涵盖以下步骤:首先,数据库的扫描,寻找项集中涵盖的频繁项集。其次,按照频繁项集进行最小置信度构造。
1.2 优化Apriori算法
Apriori算法优化核心内容是扫描数据库,形成矩阵储存事务信息,之后按照权值对所有事务支持度进行计算,同时根据支持度计算结果对事物矩阵展开排序处理,和阈值之间逐条对比,若是事务支持度比阈值小,则进行删除处理,之后分解事务矩阵,最后开展形成频繁项集操作[3]。
扫描音乐数据库形成D(事物矩阵)从,每行记录一个事务与相应权重,之后进行排序编码处理,将低于阈值事项删除,使行向量[d1,d2,d3,…,dj]变为0与1,进而能够按照频繁项集升序对H进行分解,变为子矩阵,数量为P个,即H1,H2,H3,…,Hp。
扫描H第p个列向量,即Dp=(d1p,d2p,d3p,…,dqp),对dip依次判断,如果值为1,那么选取H中前p项,产生Hp。
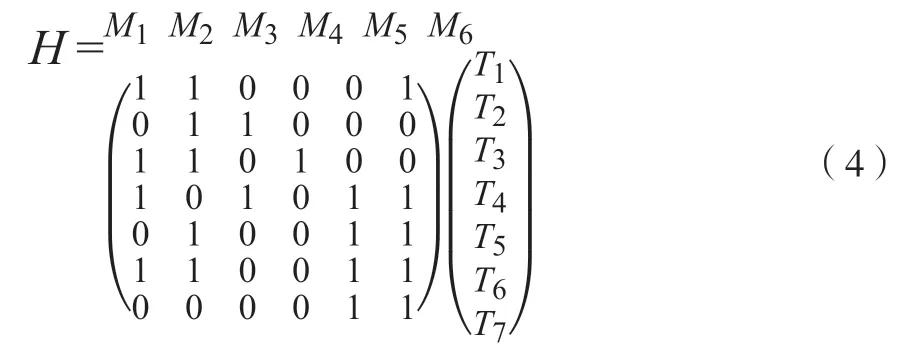
借助简单例子对具体过程中进行说明,将支持度阈值设定为2,音乐事务如下:T1:M1,M2,M6。T2:M2,M3。T3:M1,M2,M4。T4:M1,M3,M5,M6。T5:M2,M5,M6。T6:M1,M2,M5,M6。T7:M5,M6。
按照相应公式,根据权值能够获得Ti子集支持度,

其中,k代表Ti长度。
扫描数据库,获得事务矩阵:

借助计算获得行向量与列向量,分别为{3,2,3,4,3,4,2}、{4,5,2,1,4,5},进行降序排列处理,获得H’:

2.1 以用户为基础的音乐标签
音乐标签多样性、语义性特点良好,良好音乐的标签可以充分代表音乐内容,将音乐关键特征充分体现出来,专家标注方式已经无法满足多样化、海量音乐内容,当前,一般选择用户打标签模式,然而此种方式也存在一定问题,即在用户数量增长过程中,同时标准不够统一,用户能够选择任意标签对同一音乐表达理解,所以,导致标签信息数量持续增长,而有用信息降低。
针对此类音乐标签,其可以将受众对于音乐最直接反映体现出来,为推荐算法提供良好的依据,但是也存在信息杂乱、不统一等问题。
2.2 音乐标签
因为受众标注音乐时,存在不规范、不相关以及其他问题,使用此类标签过程中,需要将噪声信息删除,保留有效信息,可以借助多维对应方法将标签噪声删除。
对于用户日志,一般借助听歌记录并不能够对其标注信息进行获取,可以借助MBID接口获取标注信息。开展数据采集工作时,若是同一标签对不同音乐进行标注,则应该自动干预,此种现象表明不同音乐具有一定相似性,可以借助jaccard相似系数对各个音乐相似度进行计算,见下式:

其中,代表集合中的标注标签。
处理音乐标签时,主要目的就是删除被标注标签的噪声,对有效标签进行保留。借助多维对应分析法开展分类数据分析工作,对底层结构数据集进行检测以及表示,标签数据能够以分类数据角度分析,然而对各类标签若是看作一类标签,则会由于数据库中信息维度过高,影响数据计算效果,因此应该开展数据降维处理,标签点按照降维数进行映射处理,因此可以选择余弦相关性度对2个维度相似性进行计算。
借助A1代表音乐标注第一个信息,A2代表第二个信息,最终计算结果显示,相应向量夹角即A1相似度与A2相似度,最终能够删除弱相关性的标签。
处理音乐标签时,借助删除无效内容,并对标签信息中高频率出现标签信息进行记录,进而得到有效用户标注与音乐标签,此种方式能够客观反馈音乐信息,也是用户兴趣点。
受众兴趣度涵盖以下类型:首先,显性类型,受众主动提供给系统,体现出受众主观意愿。其次,隐性类型,借助分析受众听歌行为获取,可以将用户听歌行为习惯体现出来。因为显性兴趣度能够直接获取,所以主要分析隐性兴趣度。
数字音乐属于被推荐商品,其含有商品共性,另外个性较强,特别对于推荐系统,此种个性导致无法根据普遍推荐算法开展音乐推荐工作。以用户行为层面分析,受众可以通过多样化方式操作音乐,比如受众对于一首歌曲听的时间可以体现出受众对于该歌曲的喜爱程度,这与推荐时借助用户购买记录获取相似商品存在一定差异。对普通受众兴趣度计算展开合理优化,开展计算工作前,进行几点假设:
第一,受众会点击收听感兴趣音乐。
第二,受众对于歌曲的操作行为体现出其在音乐方面的兴趣度。例如,受众听取一首音乐的时长体现出其兴趣度,若是其听完该音乐,代表其对于此首音乐比较感兴趣;
若是收藏此首音乐,则体现出受众非常感兴趣。
第三,同类受众在未知音乐中具有相同音乐度。
4.1 Last.fm数据集
Last.fm支持受众自定义对音乐标签进行处理,同时对受众收听信息进行记录。现阶段,公布的信息中用户记录达到36万个,随机挑选4128个信息,其中音乐为231453首,音乐标签为13246个。
4.2 评价标准
评价推荐结果过程中,以Recall(召回率)与Precision(准确率)为标准,见下式:
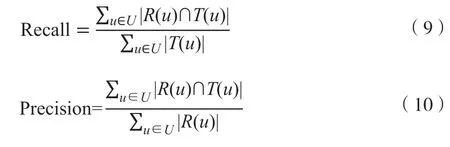
其中,T(u)代表原始数据集受众感兴趣音乐几何,R(u)系统推荐给受众的集合。
另外,为了对推荐结果多样性进行验证,选择相似度计算方法进行验证,见下式:
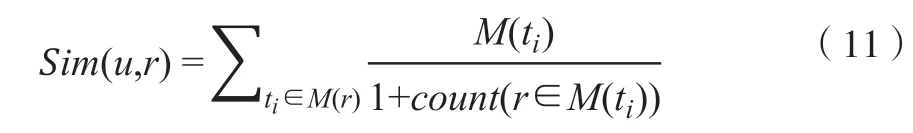
其中,1+count(r∈M(ti)代表ti音乐标签使用数,M(ti)代表ti所标注音乐集,ti代表音乐标签。
4.3 实验结果
选择UserCF(协同过滤算法)、聚类UserCF和本文方法展开召唤率、准确率对比,结果如下:聚类UserCF:Precision为72%,Recall为29%。UserCF:Precision为64%,Recall为20%。Apriori+:Precision为79%,Recall为26%。
通过实验结果能够发现,准确率对比方面优于所对比方法,比聚类UserCF方法召回率略低。
对于推荐算法,Playcount算法主要是对受众潜在兴趣度着重挖掘,采用Playcount方法和各项结果展开对比。
对于推荐系统,音乐结合应该适量,若是推荐结果较多则会导致针对性不足,进而导致受众在推荐结果方面丧失耐心,若是结果较少则会导致受众感兴趣内容遗漏,所以对于推荐集合音乐数量进行设定:25、23、20、18、15、13、10、8、5,结果准确率,Playcount为:0.851、0.852、0.857、0.861、0.865、0.876、0.881、0.898、0.910。Apriori+为:0.879、0.882、0.882、0.866、0.873、0.876、0.885、0.910。
结果召回率分别如下:Playcount为:0.26、0.25、0.24、0.23、0.18、0.16、0.13、0.08、0.03。Apriori+为:0.28、0.27、0.26、0.24、0.20、0.17、0.14、0.09、0.03。
通过以上实验结果能够发现,对于准确率,推荐次数在18次以内时,两种方式并无较大差异,然而超出18次时,本文方法推荐效果比Playcount方法效果突出,体现出基于推荐数量相同条件下,本文方法形成的推荐集合受众感兴趣音乐占比优于Playcount。对于召回率,本文方法优于Playcount,体现出本文方法形成的推荐集受众感兴趣的音乐数量比Playcount高。
相似度如下:Playcount为:0.96、0.94、0.92、0.91、0.90、0.88、0.87、0.86、0.85。Apriori+为:0.83、0.83、0.82、0.80、0.80、0.79、0.78、0.76、0.75。
通过上述数据能够发现,Playcount方法具有较高相似度,极易出现同质化问题。但是本文方法具有较低相似度,不仅对受众相似兴趣进行充分考虑,同时体现出推荐多样性。
综上所述,根据受众兴趣度计算,对推荐结果多样性进行考虑,选择优化Apriori算法对目标音乐和音乐库之间相似度,充分保证准确率,并且提高推荐结果多样性。对音乐标签开展噪声处理,留下有效标签。并基于受众兴趣度,设计推荐系统流程,有效提高推荐效果。实验选择Last.fm进行仿真实验,最终结果可以满足使用要求。
猜你喜欢 项集阈值标签 基于哈希表与十字链表存储的Apriori算法优化计算机应用与软件(2022年7期)2022-08-10改进的软硬阈值法及其在地震数据降噪中的研究重庆大学学报(2022年2期)2022-02-28土石坝坝体失稳破坏降水阈值的确定方法建材发展导向(2021年19期)2021-12-06基于小波变换阈值去噪算法的改进计算机仿真(2021年6期)2021-11-17Sp-IEclat:一种大数据并行关联规则挖掘算法哈尔滨理工大学学报(2021年4期)2021-10-07含负项top-k高效用项集挖掘算法计算机应用(2021年8期)2021-09-09改进小波阈值对热泵电机振动信号的去噪研究智能计算机与应用(2020年4期)2020-08-31不害怕撕掉标签的人,都活出了真正的漂亮海峡姐妹(2018年3期)2018-05-09让衣柜摆脱“杂乱无章”的标签Coco薇(2015年11期)2015-11-09科学家的标签少儿科学周刊·少年版(2015年2期)2015-07-07栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: