基于动态探针的企业数据空间实体关联构建方法
陶 冶,郭帅童,丁香乾,侯瑞春,初佃辉
(1.青岛科技大学 信息科学技术学院,山东 青岛 266071;
2.中国海洋大学 信息科学与工程学院,山东 青岛 266000;
3.哈尔滨工业大学(威海) 计算机科学与技术学院,山东 威海 264209)
企业业务系统普遍存在信息共享程度低、信息与业务流程和应用相互脱节等问题,容易导致企业内形成信息孤岛[1]。特别是工业软件公司为了实现工业流程和技术的程序化,需要庞大的技术数据支撑,这不仅需要企业内部解决信息孤岛问题实现数据共享,还需要与很多不同的工业企业的数据进行融合[2]。因此,为了实现企业内部或外部的数据融合,一些企业开始着手搭建数据空间,试图将企业资源计划(Enterprise Resource Planning, ERP)、客户关系管理(Customer Relationship Management, CRM)、制造执行系统(Manufacturing Execution System, MES)等工业软件进行整合,从而解决“信息孤岛”问题。
数据空间构建过程中的一个主要问题是如何准确建立实体之间的关联,即将多源数据库中的异质异构数据通过实体匹配整合为一个全面的企业数据空间。尽管可以通过字典或语义库的属性列语义匹配、利用列内容相似性判断[3-4]和使用朴素贝叶斯学习算法计算属性列相似概率等方法发现实体之间的关联,但是在应对海量数据时,上述方法存在普适性差、响应慢和准确率低等问题。
为提升海量数据之间相互关联的准确性、完整性和时效性,一方面从数据的物理结构入手,通过将数据元素的表示和关系抽取出来作为模式信息,通过模式匹配挖掘数据之间的相似关系。DOS REIS等[5]从多源异质的大规模关系型数据库中使用结构化查询语言提取数据库名、模式名和表名等信息作为元数据集,集中保存于数据库中。通过欧式距离分析元数据集之间的关联性,从而建立源数据库之间的关联关系。BERLIN等[6]提出的系统主要基于贝叶斯学习,将领域专家“映射”到属性知识数据库。对匹配对象的属性根据属性知识数据库的信息一一比较,得到量化值。然后基于最小成本最大流量网络算法得到对象之间的总体最佳匹配。对于模式匹配中的本体语义相似性问题,孙海霞等[7]通过研究基于距离、信息内容、属性和混合式的语义相似度模型,发现将比较词语转换成本体中的概念词,进行语义相似度计算,可以对某领域的本体语义实现有针对性的准确的有效衡量,从而提高了本体语义分析在模式匹配中的准确度。模式匹配在处理少量数据时能够根据所分析的信息有效地区分数据之间的关联,且由于分析的元素固定,处理速度不会随数据量的改变而显著变化,以较少的资源就可以实现数据之间的关联匹配。但是当数据量呈指数增长时,由于模式信息的数量一定,不同类别数据的模型信息相似或相同的概率急剧增大,导致模式匹配分析数据的区分度效果减弱。
另一方面数据自身可以作为数据的实例信息,从中挖掘数据之间的相似关系。如BAKHTOUCHI等[8]针对基于实例的数据融合中存在的数据冲突问题,提出了将冲突分为不确定冲突和矛盾冲突两类,并分别给出了解决方案,实现了对同一表示形式的重复数据进行融合,同时解决了同一属性的不同值之间可能存在的冲突等问题。RAHM等[9]给出了如何将模式匹配中的名字和描述匹配等解决方案用于元素级别的实例分析的迁移思路。XU等[10]、SUTANTA等[11]针对实例的不同数据类型,提出了如何将实例数据进行分类,并对不同类别的数据如何建立数据关联提出了系统性的理论框架。实例分析与模式匹配在处理海量数据时,对数据融合能够保持一个较好的区分度,但是这往往需要耗费较长的分析时间。此外,当数据发生改变,特别是新增数据时,实例分析往往要耗费大量的时间和运行资源修正数据关联关系。
除此之外,随着深度学习与日志的结合,一些用日志来刻画用户与某类物品或某种事情之间关联的研究也受到了大量关注。张有等[12]通过连续采集用户的各种行为记录,生成大规模异构日志数据,从而挖掘用户的行为模式,然后通过行为模式是否改变来检测用户异于以往的行为特征,实现内部威胁检测这一目标。MOHANTY等[13]使用物联网收集网络日志文件进行清洗和学习,通过建立用户画像和保存相似信息,提出了基于粗糙模糊聚类的网页推荐系统,实现了为用户推荐电子商务购物网站的目的。日志中含有数据之间的关联关系,但日志通常只涉及部分业务数据,缺乏完整性,难以全面反映数据间的关联关系。
综上所述,企业发展中不断增加的数据源,导致数据的规模和类别不断增加,而模式匹配、实例分析和日志挖掘等方法从单一维度对数据进行分析,可能存在无法充分利用数据的多样性、分析不全面和浪费大量资源等问题,无法高效准确地从海量数据中挖掘有价值的信息,帮助企业更好地发展。针对这些问题,本文通过整合模式、实例和日志,从多维对数据进行分析,充分利用数据的多样性建立实体关联。
通过在不同系统的业务逻辑层与数据访问层之间部署动态探针,获取数据库数据和日志信息。然后从数据结构、实例和日志这3个维度建立相应的模型,刻画实体之间的相似程度,给出实体之间在不同维度上的相似值。数据在多个维度上的相似值之间不具备可比较性,本文采用基于模糊逻辑的方法[14-15],对不同维度上的相似值进行归一化处理,使其能够相互比较,从而得到实体之间关联的最佳匹配结果。
如图1所示为实体关联映射模型,将企业业务系统中A和N等部门的多源数据如A1和N1等分别映射为数据空间的A1和N1等,属性aij,nij分别为对应的子节点。在此前研究中[16],笔者提出一种根据不同系统的全链路访问日志,并据此建立了跨域实体间的可视化动态关联模型,以节点表示数据库中包含有的属性,线性粗细代表属性之间关联的强弱。在数据空间的实体关联模型可依照类似模型进行可视化,具体地,根据可统一衡量的归一化实体间的相似值,建立实体之间的关联关系,并通过线条的粗细体现实体之间关联的强弱。如R1:sim=1表示其关联的实体a13和n11之间的相似值为1,R2:sim=0.83表示其关联的实体a21和n11之间的相似值为0.83,通过线条的粗细直观清晰地展示了实体a13和n11之间的关联比实体a21和n11之间的关联强。

如图2所示,首先在企业各业务系统如ERP,CRM等的业务逻辑层和数据访问层中间分别部署动态探针,实时监听并获取业务执行时产生的数据。为便于使用需要,将数据进行持久化保存,业务逻辑层以日志的形式保存,其余数据使用关系型数据库存储。企业数据具有规模巨大和数据类型繁多等特点,根据数据的特征和性质对数据进行预分类,从而加快数据的处理并提高实体间匹配的准确度。动态探针获取的数据分为数据库模式、数据库实例和SQL日志,分别从以上3个维度进行分析并分别计算实体之间的相似值。从属性名和约束两方面进行模式匹配分析;实例分析根据数据类型的不同分为数值、字符和长文本3种分析方法;日志分析根据动态探针所捕获的SQL语句中包含的属性关联信息计算实体之间的相似值。最后,基于模糊逻辑分析器,根据实体在不同维度上的相似值,对实体之间的相似性进行归一化计算,从而在数据空间建立有效的实体关联。
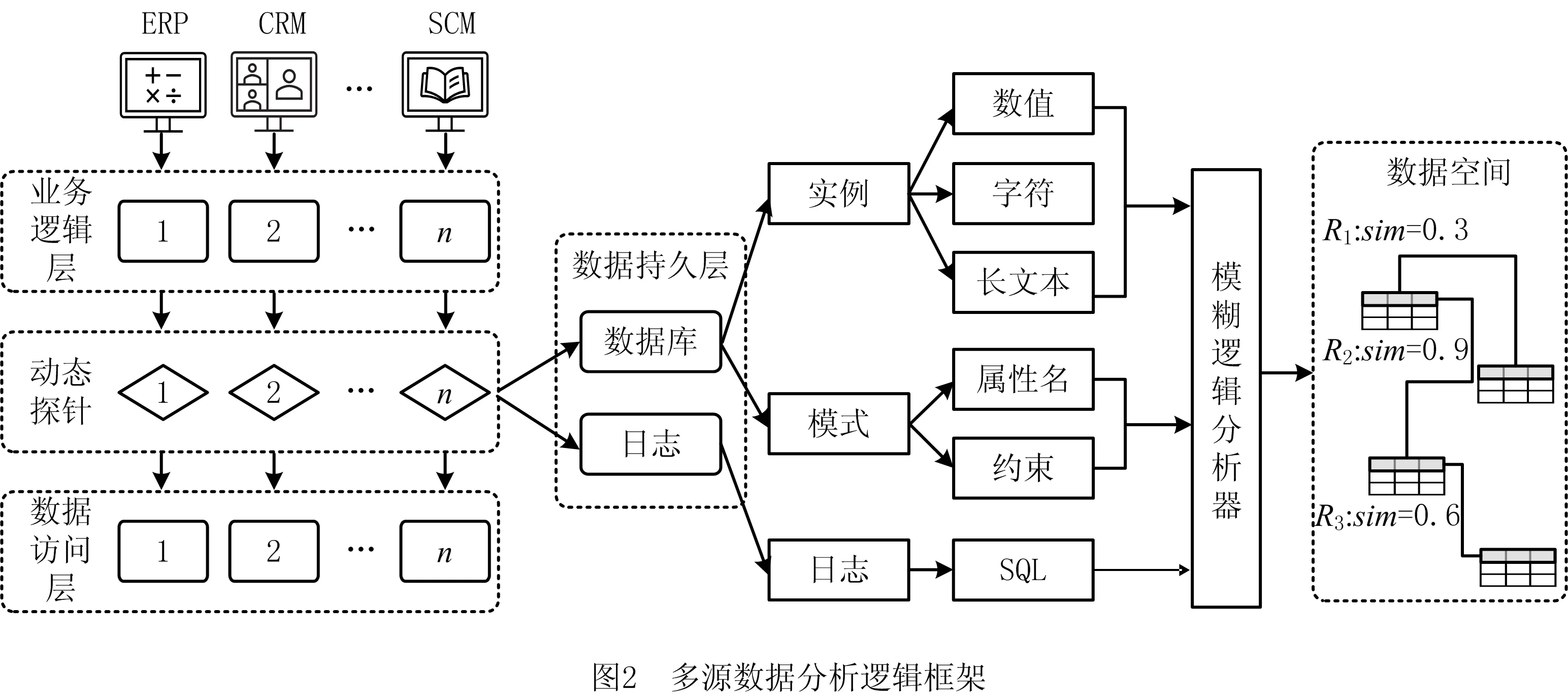
1.1 模式相似模型
虽然由于应用场景和命名规范等因素导致数据库设计人员所开发的数据库千差万别,但是数据库设计中一般包含表和字段名、表结构和数据类型等内容。因此,提取数据库中模式信息的属性名和约束作为模式相似模型的分析内容,衡量实体之间的相似性。
1.1.1 属性名
属性名分析分为朴素文本相似度和文本语义相似度分析两种,属性名之间的文本相似度计算方式为编辑距离算法,文本语义相似度通过语义库的方式计算。编辑距离指在两个单词w1和w2之间,由单词w1转换为单词w2所需要的最少单字符编辑操作次数[17-18]。根据编辑次数定义朴素文本相似值:
(1)
式中:l1,l2为属性名w1和w2的字符长度;D为属性名w1和w2的编辑距离。
对于同一实体的描述可能有不同的表达方式,如企业数据库中记录某上游公司的信息,其属性名由于场景的不同可以命名为CompanyID和SupplierID。针对此种情况,若只通过朴素文本分析很难发现属性名之间的相似关系。因此,采用基于语义的相似度分析方法,具体地,对属性名建立如图3所示的树状语义层级关系,通过属性名在树状图中对应的位置计算单词之间的相似性。

基于语义的相似性计算公式为:
(2)
式中:N1和N2分别表示单词w1,w2与最近公共父节点词w间的最短路径;H表示从w到根节点的最短路径。最终属性名相似值为朴素文本相似度和文本语义相似度中的最大值,如式(3)所示:
Sname=Max(Splain,Ssema)。
(3)
1.1.2 约束
数据库中的列在建立时,设计人员会遵循一定的设计原则,如合适的数据类型、是否为空等。通过约束进行列与列之间的相似匹配,需要筛选有代表性的约束,本文从数据库中的众多数据约束信息中筛选出属性列类型、是否是主键或外键、是否允许空值和是否有注释作为特征元素。

表1 模式规范特征
假设需要进行约束相似度判别的两列分别为A和B,Ai和Bi分别是两列属性对应的第i个候选约束的取值,令:
(4)
式中n为候选约束个数,则列A与列B的属性约束相似度为
(5)
1.1.3 模式相似值
由于模式分析器中包含属性名和约束分析两种,采用加权平均的方式,将式(6)的结果作为模式相似值:
Sschema=α·Sname+(1-α)·Scons,
α∈[0,1]。
(6)
式中α根据实际情况,调整参数属性名Sname和约束Scons在模式分析中所占的比例。
1.2 实例相似模型
由于描述同类实体的数据集存在相似性,如取值区间、极值和关键词等,从数据集中提取信息刻画实体的基本特征,根据数据的特征信息判断数据之间的相似性强弱,从而建立实体之间的关联。其中数据类别是数据集的显著特征,数据类别的不同导致选择的刻画数据集特征的属性具有差异性。有针对性地对不同类别的数据集建立差异化的特征提取方案,可以提高实体间关联匹配的准确性。对数据库中的数据类型按表2进行归类,不同类别的数据对应不同的处理方案,一般数据类别不同的实体之间不相似。

表2 数据类型归类
根据数据类型的不同,实例分析可以分为数值型、字符型和长文本型3种。其中数值型指表2中的整型和浮点型,字符型根据文本的长度不同又分为字符和长文本两类。对数据进行分类聚类后按照图4所示流程分析数据之间的相似性。

1.2.1 数值型
对于统计性标量,如加和、均值、方差、中位数等,可以从数值分布的角度考虑列与列之间的相似性。为了从不同方面体现数值型标量的特征,重点从以下3个方面考虑特征的选取,能够界定数据范围的最大值和最小值,反映数据主要分布情况的平均值、算数中位数和众数,能够反映数据离散程度的样本标准偏差,这些指标元素对数据量变化不敏感,可以用来作为计算列相似性的特征元素,而对于非空值的数量和数据的累计总和等指标,会随数据量的变化而显著变化,因此不适合作为特征元素。最后,计算每列对应的特征向量,代入余弦相似度公式,将结果作为数值型的相似值。
1.2.2 字符型
字符型指短文本内容,使用“词频—逆文本频率”作为相似度计算算法。首先,将需要判断相似度的列内容合并,作为单独的一个数据集;然后,求每列的列内容对应的向量;最后,将特征向量代入余弦相似度公式,计算字符型的相似值。
1.2.3 长文本型
长文本型指长文本内容,将列中的记录映射为向量,使用自编码建立模型,根据模型计算列之间的相似值。假设A、B两列均为长文本列,如图5所示,为了防止在根据数据建立模型过程中,数据集的数量相差过大导致模型出现过拟合等问题,需要确保数据集的数量在同一量级上,因此对A、B两列随机抽取k条记录作为抽样集。自编码的输入要求是向量,因此将抽样集中的文本转化为向量。然后将其分为训练集和测试集,自编码分别使用训练集建立模型后,根据测试集的准确率计算A、B列的相似性。

自编码模型计算长文本列相似度,如算法1所示,自编码器1中的输入参数x1、x2和y对应图5中向量集中1、2和4所代表的数据,自编码器2中的x1,x2和y对应图5中向量集中3、4和2所代表的数据,输出参数分别记为λ1,θ1和λ2,θ2。根据测试集在自编码器的准确值来计算两列相似值为:
(7)
算法1长文本相似度计算方法。
输入:
训练自编码器的数据集中的训练集x1,测试集x2;
用于测试自编码的测试集y,
文本相似的阈值ω;
输出:
x2对应的测试准确值λ,
y对应的测试准确值θ。
1.a_train, a_test=x1, x2; s_a_num, s_b_num=0,0
2.b_test=y;
3.a_num, b_num=len(a_test), len(b_test);
4.input=a_train;
5.encoded=Dense(input); //创建编码器
6.decoded=Dense(encoded); //根据编码器创建解码器
7.autoencoded=Model(input, decoded); //训练自动编码器
8.a_test_predict=autoencoded(a_test); //用x2测试训练过的自动编码器
9.b_test_predict=autoencoded(b_test); //用y测试训练过的自动编码器
10.FOR a, b ina_test, a_test_predict: //成对取测试集x2和自动编码器处理后的数据集
11. IF similarity(a,b)≥ω: //计算数据的相似值并与阈值对比,统计大于阈值的数量
12. s_a_num++

14.FOR a, b inb_test, b_test_predict: //成对取测试集y和自动编码器处理后的数据集
15. IF similarity(a,b)≥ω:
16. s_b_num++

1.3 日志相似模型
分层架构中的业务逻辑层主要是对实体的属性和行为进行封装,虽然在不同业务逻辑中实体的表示方式不尽相同,但是同类实体具有类似的属性和行为。通过分析业务逻辑层的载体日志中关于实体的信息,计算实体之间的相似值。日志记录的SQL命令含有列之间的关联关系,可以作为衡量列相似度的分析依据。通过统计日志文件中等价关系的次数可以得到列与列之间的相似度。
假设a,b为对比列,则a,b列的日志相似值计算公式为:
(8)
式中:Na,Nb为日志中分别包含a,b值的SQL命令出现的次数;Nab为日志中同时包含a,b属性的SQL命令出现的次数。
1.4 模糊逻辑相似性度量
根据前文所述,用所提模型对数据进行计算,能够得到模式、实例和日志3个维度的相似值,由于不同维度上的相似值不具备直接的可比较性,需要将其统一成可直接比较的值。一般能够将多维的数值转为一个数值的方法有德尔菲法[19]、加权平均和模糊逻辑等。德尔菲法依赖于特定领域的知识,当数据来源不定时其无法与数据很好地适配,而加权平均由于其形式固定,对于数据处理的方式比较单一,无法充分利用数据的特征。模糊逻辑中可以包含专家领域的知识[20]且其对数据进行处理时能够使用多个函数进行数据拟合,其适配性和适应性相对较好,因此选择模糊逻辑来将多个维度的相似值进行归一化处理。
设A和B为进行相似性判别的两列,将上述3个维度的分析结果作为模糊逻辑的输入,并计算隶属度。对数据进行模糊化后,判断其是否符合模糊规则。然后计算所有满足模糊规则的情况,将计算结果进行反模糊化后便可以得到归一化的衡量列与列之间的相似值。以图6为例,首先A和B经过上述模式、实例和日志分析得到其在对应维度上的相似值:scheme, instance, log分别为0.6、0.7和0.8,然后将相似值经过一系列的模糊操作,最终得到A和B之间的相似值为0.71。
为验证所提框架的可行性,收集某企业供应商的数据集进行验证。将各个供应商根据企业要求提供的信息,如产品报价、产品供应等信息整合到一起,通过与人工整合的结果进行对比,验证模型的可用性,并记录分析模型在运行过程的表现情况。硬件环境为:Intel(R) Xeon(R) Silver 4210 CPU @ 2.20 GHz,64 GB RAM,RTX2080Ti*4。

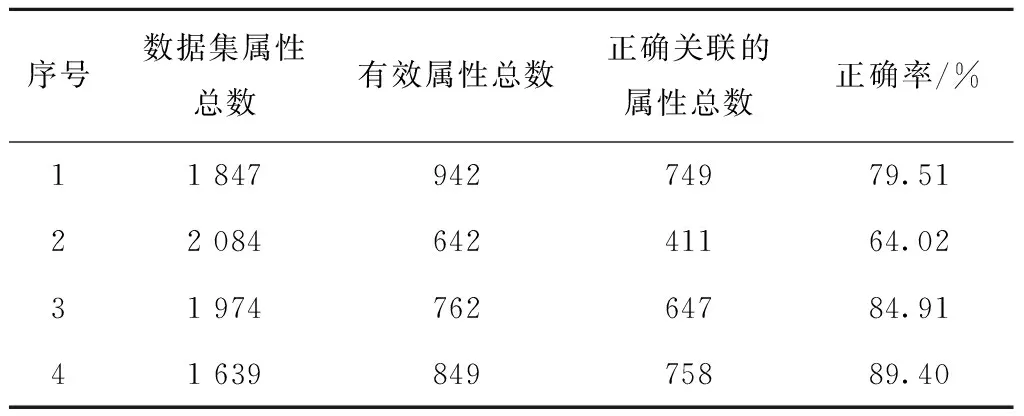
表3 数据匹配结果
设计如下实验:将供应商提供的数据使用本节所设计的模型分析数据之间的关联关系,实现数据自动导入到汇总表中(汇总表中需要预先存在需要导入的属性及其对应的部分数据)。表3是分别选取供应商数据中3 000条记录的匹配结果,其中每一行是每个供应商的匹配结果信息。数据集属性总数指供应商提供的数据属性的总数,有效属性总数是指能够与汇总文件中某一列属性对应的数据,正确关联的属性总数指的是将每个供应商的数据通过模型匹配后,正确整合到汇总文件中对应的列数,正确率是正确关联属性的数目与有效属性总数的比值。
由结果可知,数据匹配的准确度最佳表现能够达到89%左右,能够很好地作为辅助工具进行数据的匹配,而对于第二列数据匹配的准确度较低的结果进行分析,发现其供应商提供的数据中专有名称和缩写使用较多,且由于其业务涉及比较单一,内容相似度较高,导致模型分析中的模式匹配结果准确率不高,从而导致结果不理想,后续可以通过优化模式匹配中的语义分析提高准确性。
2.1 数据空间实体关联不同方案对比实验
抽取收集的供应商数据中的有效数据作为一个整体,并标注其对应汇总表中的位置,作为计算准确度时的标准,从每个供应商的有效数据中等比例抽取相同数量的列作为样本,然后分别基于模式、实例和本文所提的基于模糊逻辑的框架进行数据匹配实验,从时间和准确率两方面比对不同方法之间的优劣。
从图7a中可以看出,在不同数据量的情况下,基于模式的实验所用时间最少,且时间消耗变化不明显,基于实例的方法由于内容分析全面,数据匹配时间在相同数据量下大幅增加,而本文所提方法虽然包含实例分析,但是由于在对实例分析时会对数据分类分析,减少了数据之间相互匹配的数量,从而消耗的时间比只有实例分析的少。
从图7b中可以发现,在实验样本低于600时基于实例的数据匹配准确度最高;
本文所提方法在800列后一直保持最高准确率;
基于模式的方法在数据量为1 400列后由于分析元素有限,数据规模变大导致同质数据增多容易发生误配事件导致数据匹配准确率下降。整体而言,随着数据量的增多,所有分析方法的数据匹配准确率呈上升趋势,这是由于在等比例抽样时,当样本较少时供应商之间对应的相似数据被抽到的数目较少,导致误配情况发生的可能性增大;
而当抽样数据增多覆盖整体数据的比例上升时,误配情况大幅减少,从而数据匹配的正确率逐渐提升。
结合图7的对比实验可以发现,在数据量适中的情况下,本文所提方法可以在短时间内得到较高的准确率。

2.2 实例分析中长文本验证实验
为了研究实例分析中不同维度的长文本在自编码模型中的表现情况,在本节实验中,通过收集企业简介作为数据集,并将其分为两列,使用实例分析中的长文本分析方案,通过改变向量维度这一变量进行验证。
从图8a可以看出,在相同数据量情况下,维度越高,实验所用时间越多。在数据行数是200 000时,很明显,维度是1 024所消耗的时间大约是维度是128的10倍。由图8b可以发现,在数据量较少的情况下,若维度过高会降低准确率。这是由于自编码的原理是通过对数据进行降维提取关键信息,当数据规模小时,长文本中压缩提取的数据特征有限,则高维的特征向量会混杂大量的噪声数据,导致准确率低。随着数据量的增加,从数据中可以提取出更多的数据特征,高维的特征向量可以更好地表示文本,因此有更高的准确率。结合图8可以发现,在数据行数为30 000时,维度是128和256的较低维度的数据匹配准确率能维持一个较高的值且耗时较短,但是当数据量增加到30 000以上时,维度是512和1 024的高维度的数据匹配准确度能够随数据量的增多而显著变高,但是所耗时间也随数据量的增大而显著增多。

本文提出一种基于模式、实例和日志的混合实体匹配模型,通过前置探针获取数据,采用多层分析框架从模式、实例和日志3个维度完成相似度计算,并基于模糊逻辑推理将多个维度上的相似值进行整合归一化表示,根据模糊化得到的最终标准化相似值作为衡量数据匹配的标准,从而为数据空间构建过程中的实体融合提供参考依据。实验结果表明,与先前基于模式或实例的单一匹配方法相比,本文所提出的模型在准确率和处理大规模数据所消耗的时间等方面有更好地效果。后续研究将聚焦如何建立数据和权重之间的映射关系,建立权重分配指导方案,从而更好地处理多源异构数据中数据的随机性和多样性对结果准确度的影响这一问题。
猜你喜欢 数据量日志实例 一名老党员的工作日志华人时刊(2021年13期)2021-11-27读扶贫日志诗选刊(2020年12期)2020-12-03高刷新率不容易显示器需求与接口标准带宽电脑爱好者(2020年19期)2020-10-20雅皮的心情日志思维与智慧·上半月(2018年10期)2018-11-30雅皮的心情日志思维与智慧·上半月(2018年9期)2018-09-22AMAC软件导刊(2018年3期)2018-03-26电力营销数据分析中的数据集成技术研究科技与创新(2014年11期)2014-08-21完形填空Ⅱ高中生学习·高三版(2014年3期)2014-04-29完形填空Ⅰ高中生学习·高三版(2014年3期)2014-04-29固定资产管理系统对物流管理的促进和发展商场现代化(2009年16期)2009-06-22栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: