基于文本特征增强的电力命名实体识别
刘文松,胡竹青,张锦辉,2,刘雪菁,林 峰,俞 俊
(1. 南瑞集团有限公司(国网电力科学研究院有限公司),江苏省南京市 211106;
2. 江苏瑞中数据股份有限公司,江苏省南京市 211106)
命名实体识别(named entity recognition,NER)指识别文本中具有特定意义的专有名词[1],分通用和特定两大类。通用NER 一般指识别人名、地名、机构名等名词;
特定NER[2]指识别电力、财经、司法、海洋、医疗等特定行业的名词。电力命名实体识别具有鲜明的行业特定语义,在电力设备管理[3]、二次设备诊断[4]、电网调控[5]、资源中台元数据建模等场合有着广泛应用,是文本分析的第1 步。以“柔性直流”为例,如将其识别为“柔性”和“直流”,即使采用实体消歧算法也无法有效纠正,直接影响后续处理[6]。因此,如何针对中文电力命名实体的特点,进一步提升识别效果,值得深入研究。
中文电力命名实体的特点包括:1)语料规模小,无公开、标准数据集;
2)实体嵌套,表现为实体组成复杂且长,如“静止同步串联补偿器”;
3)实体缩写,表现为特定简称,如“柔性直流”简称为“柔直”。针对这些特点,传统的模板法严格依赖于特定场景下的人工特征选择和规则设计,无法有效解决实体缩写和嵌套的问题。经典的机器学习方法加强了特征挖掘能力,但性能提升有限[7-10]。随着深度学习兴起,双向长短时记忆(bidirectional long short-term memory,BiLSTM)网络与条件随机场(conditional random field,CRF)[11-12]相结合,在大规模语料的支撑下,在通用命名实体识别方面取得良好效果。文献[13]针对上下文学习时的噪声影响,引入注意力机制(attention mechanism,AM)对实体信息进行动态加权。以BiLSTM-AM-CRF 为代表的NER 模型已逐渐成为研究主流,文献[5]首次将其用于电网调控领域的实体识别,应用于电网核心生产业务。
针对特定NER 的性能提升,现有研究可以主要概括为以下4 个方向:
1)优化BiLSTM-AM-CRF 的向量输入。常见方法是用词向量工具Word2vec[14]获取文本的向量表达。Word2vec 计算单词/单字在文本中的静态分布概率,也就是用单词/单字的静态分布概率来量化表示文本。文献[15]提出基于语言模型的词向量(embedding from language model,ELMo)[16],相 较Word2vec 引入更多的单词/单字分布的上下文特征。文献[17]提出基于Transformer 的双向编码器表征模型(bidirectional encoder representation from Transformers,BERT),BERT 依托超大 规模算力(含64 块NPU 的计算集群),充分学习33 亿单词量的语料库,获得的向量表达是动态的,可以解决一词多义问题。很多研究直接应用BERT 单字向量进行实体识别,取得较大性能提升[18]。
2)优化BiLSTM-AM-CRF 的模型构成。文献
[19]提 出 门 控 循 环 单 元(gated recurrent unit,GRU),相比长短时记忆(long short-term memory,LSTM)网络的结构更简洁,收敛速度更快,在数据集较小的场合也表现更好。文献[20]提出双向门控 循 环 单 元(bidirectional gated recurrent unit,BiGRU)并应用于实体识别中。
3)优化文本特征的表达。文献[21-22]采用卷积神经网络(convolutional neural network,CNN)来学习单词内部的字符级特征,与单词向量拼接后,输入NER 模型学习。文献[23]用CNN 处理汉字部首,获得汉字形态特征。文献[24]用CNN 处理特定领域名词后缀,获得专有名词特征。相关研究虽已运用了单词的语义信息,但未提及如何合理控制分词误差。虽然通过CNN 学习单词的字符级特征,但没有结合中文电力命名实体的特点引入更多文本特征,且未结合分词策略进行优化。
4)提出新的NER 模型结构。与BiLSTM-AMCRF 不同,文献[25]提出级联LSTM,即输入单字向量的LSTM 与输入单词向量的LSTM 构成级联网络。一方面,单字向量输入的LSTM 降低了分词误差的影响。另一方面,文本序列中所有可能组词的单词向量输入到LSTM 中,也会引入较多的无关信息。对此,文献[26]探索引入门控去噪机制来过滤无关的文本信息。
参考以上特定NER 研究,结合电力命名实体的特点,开展电力命名实体的方法研究,重点在于小规模语料条件下,进一步丰富增强构成电力命名实体的单词特征,从而提升实体识别模型的效果。据此,本文提出一种基于文本特征增强的电力实体识别方法。首先,通过预设先验词库和低粒度分词来降低分词误差带来的影响;
其次,设计词级BiGRU 学习中文单词的组成和顺序特征,结合词性、词长特征,实现单词特征增强;
最后,通过BiGRU 完成文本的实体特征学习,采用注意力机制加强与实体特征相关的信息加权,降低单字对训练的干扰,并用CRF完成文本标签的解码输出。综合上述3 个方法,提高电力命名实体识别的性能。
1.1 基于预设词库的低粒度分词
中文NER 任务包括单词、单字两种颗粒度。文献[22,24-26]提出字词联合的实体识别,但均未提到如何克服分词误差的影响。部分研究[18]为回避分词误差,直接基于单字向量训练NER 模型。但由于中文语言的特点,基于单字颗粒度训练向量时,割裂了字与词的关系,比如,“同步”拆成“同”与“步”时,含义已经不准确、不充分,用其表示文本特征是不合适的。
对于电力命名实体嵌套,其表现特点是电力专用名词由多个细粒度单词共同组成,如“静止同步串联补偿器”是由“静止”“同步”“串联”“补偿器”等名词组成。因此,重点是能保证最小粒度的单词被正确分出。而这也降低了分词的难度,尤其是降低了复杂语境下错误分词的可能。因此,本文采用预设词库和低粒度分词结合的方式,把“静止”“同步”“串联”等常用词纳入词库,基于预设词库的正向和逆向最大匹配完成分词。从可拓展性的角度,常用词最大长度不大于4。结合以上考虑,本文将183 796个电力领域常用词纳入预设词库,采用基于预设词库的低粒度分词,电力文本语料同时包含单字和单词,表达能力更强,同时可将分词误差控制在较低的范围内。
1.2 基于词级BiGRU 的单词特征增强
引入中文单词以后,充分、全面地表达单词特征,对于NER 模型学习电力命名实体的特征,从而提高整体的识别率尤为重要。为此,首先设计词级BiGRU 学习单词内部的组成和顺序特征,即单词的构造特征,单个GRU 结构如图1 所示。

图1 GRU 结构Fig.1 GRU structure
GRU 前向传播权重参数更新公式如下:

式中:σ为sigmoid 函数;
xt为t时刻输入;
rt和zt分别为t时刻重置门和更新门的输出;
ht-1为t-1 时刻隐藏 状 态;
˜h t为t时 刻 候 选 隐 藏 状 态;
ht为t时 刻 记 忆内容;
Wxr和Whr分别为重置门中当前输入xt和上一时刻隐藏状态ht-1的权重参数;
Wxz和Whz分别为更新门中当前输入xt和上一时刻隐藏状态ht-1的权重参数;
Wxh和Whh分别为计算候选隐藏状态˜h t时当前输入xt和rt⊗ht-1的权重参数;
⊗为Hadmard乘积;
br、bz、bh分别为重置门、更新门和计算候选隐藏状态˜h t的偏差参数。
结合图1 和式(1)分析GRU 运行机制:更新门zt可以组合控制上一时刻ht-1和候选隐藏状态˜h t,更新输出ht,决定过去到未来的信息量。重置门rt趋近零时,重置和遗忘上一时刻ht-1的状态信息,将候选隐藏状态˜h t重置为当前输入信息xt,即决定过去信息的被遗忘量。GRU 通过更新门和重置门的门控机制,能够保存长期序列中的信息并决定输出哪些信息。
据此设计词级BiGRU 学习单词内部的组成和顺序特征,如图2 所示:包括两个GRU 序列,每个GRU 序列包含4 个完全相同的GRU 单元,二者仅输入方向不同。可见,词级BiGRU 是针对基于预设词库的低粒度分词方法专门设计的BiGRU。中文语料经过低粒度分词后,第i个单词wi由单字ci1、ci2、ci3、ci4组成(如单词长度小于4 就填0 补齐),将对应的单字向量v′i1、v′i2、v′i3、v′i4输入词级BiGRU。此处的单字向量源于前文所提同一份中文语料,不做分词,采用词向量工具Word2vec 对单字集合{c1,c2,…,cM}进行处理,获取M个单字向量组成的集合{v′1,v′2,…,v′M}。由于训练主体是中文单词内部的单字字符,其标签设置为单字在单词内的顺序编码即可。通过GRU 序列计算,获得第i个单词wi的前向特征向量vFi和后向特征向量vBi,拼接成单词构造特征向量vSi=[vFi,vBi]。因此,相对于CNN学习单词的字符级特征,词级BiGRU 可以同时获得单词的组成和顺序特征。
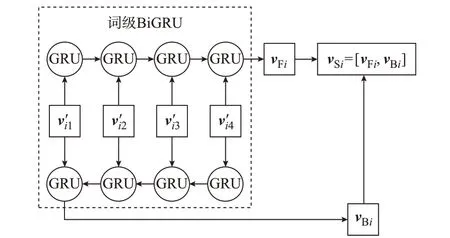
图2 基于词级BiGRU 的单词构造特征学习Fig.2 Word structure feature learning based on wordlevel BiGRU
其次,引入单词的词性特征和词长特征。词性可以表示单词的类别信息,一般情况下,中文词性可以分为12 类,其中名词、动词、形容词、数词、量词和代词是实词,副词、介词、连词、助词、拟声词和叹词是虚词。除去拟声词和叹词,共选用10 类词性。对于第i个单词wi的词性向量vpi,采用onehot 编码,向量长度为10。词长可以表示单词的边界信息,对于第i个单词wi的词长向量vli,由于最大词长限定为4,采用onehot 编码,向量长度为4。
综上所述,单词的特征增强就是引入单词的构造特征vSi、词性特征vpi和词长特征vli,与原有单词向量vi进行拼接,得向量vei=[vi,vSi,vpi,vli],将其输入NER 模型进行实体特征学习。和v′i不同,此处vi是指经过低粒度分词处理得到单词和单字后,采用词向量工具获得的向量(既包括单词向量,也包括单字向量)。对于单词向量,进行增强处理;
但对于单字向量,考虑到单字不易判别词性,且单字也不存在所谓的构造特征,因此不做增强处理。因此,vei相对于单字向量更长,在输入NER 模型前需填0对齐。
1.3 基于BiGRU-AM-CRF 的实体特征学习
基于单词特征增强,设计合适的NER 模型进行实体特征的学习,需要考虑的因素包括:1)已有文献证明GRU 在数据集较小的场合下表现更好,贴近中文电力语料规模较小的情景;
2)采用低粒度分词后,依然存在的单字可能会干扰NER 模型对实体特征学习的效果。因此,引入注意力机制,通过与实体有关的上下文信息进行加权。采用BiGRU-AMCRF 作 为NER 模 型。
基于词级BiGRU 的电力实体识别模型结构如图3 所示,电力实体识别过程为:首先,基于预设词库的低粒度分词后,获得包含N个单字和单词的文本 集 合{w1,w2,…,wN};
其 次,将 单 词 输 入 词 级BiGRU 获取单词构造特征向量,将其与词性向量、词长向量、单词向量拼接,实现文本特征的增强;
然后,将增强后的单词向量与单字向量输入到BiGRU中,进一步学习电力中文语料中单词和单字的全局分布特征和上下文关系,获得实体特征向量序列H=[h1,h2,…,hN]。BiGRU 原 理 与 词 级BiGRU原理相似,不再赘述。
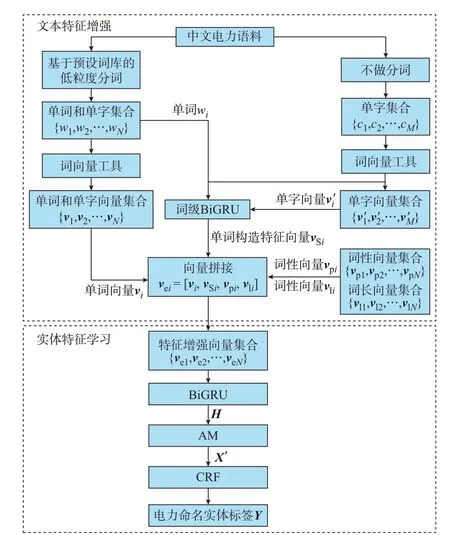
图3 基于词级BiGRU 的电力实体识别模型Fig.3 Electric NER model based on word-level BiGRU
针对单字可能造成的影响,引入注意力机制对t时刻的实体特征向量ht进行权重分配,动态生成不同连接的权重bt,从而完成与实体相关的特征加权,计算最大概率值的标签并输出t时刻的注意力状态向量x′t。注意力机制公式如下:

权重bt=[bt1,bt2,…,btD]的计算公式如下:

式中:etj为t时刻通过tanh 激活函数获得的向量元素;
α、β、γ为权重;
btj为t时刻实体特征向量ht第j个维度的权重;
D为BiGRU 维数;
k为求和变量。
通过CRF 建立标签相关性,解码输出最后标签。输 入 注 意 力 状 态 向 量 序 列X′=[x′1,x′2,…,x′N],可得预测标签序列Y=[y1,y2,…,yN]的转移概率p(Y|X′)为:

式中:S(X′,Y)为注意力机制输出状态序列经过线性链条件随机场后预测得到的标签序列预测分数;
pi,yi为 第i个 位 置 判 为 标 签yi的 非 归 一 化 概 率;
Ayi+1,yi为标签yi+1转移到yi的概率。
根据式(4),训练过程中损失函数表示为:
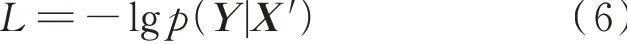
采用Viterbi 算法,通过动态规划寻找概率最大路 径,实 现 预 测 标 签 序 列Y=[y1,y2,…,yN] 的求解。
训练开始时,词级BiGRU 的参数采用Xavier uniform 进行初始化,并在训练过程中持续从后续网络中获得反向传播的梯度信息,从而进行该部分参数的优化。梯度信息来源于模型的损失函数,即将CRF 的动态规划解码结果(本质是预测标签的概率分布)与真实标签的对数似然函数作为损失函数,损失函数对当前参数的偏导即为参数的梯度,通过沿梯度方向调整参数以使对数似然函数最大化,实现预测标签的概率分布尽可能接近真实标签,从而提升整体训练效果。
2.1 实验数据和评价标准
考虑到电力领域暂无公开的标准语料数据集,而已有的公开数据集缺乏电力专业特色,无法验证方法的有效性,因此选用国网电力科学研究院的研究报告、专利和论文共900 份作为语料,定义三大类电力实体类型,包括652 个电力行业机构、754 种电力设备及材料、1 984 项电力技术,涵盖电气技术、电力工程材料、水力发电、火力发电、风力及太阳能发电、环境保护与劳动保护等9 类专业领域,涉及双碳和新型电力系统、电力自动化及继电保护、电力信息通信、特高压输电及柔性输电、发电及节能环保、轨道交通及工业自动化等25 种技术类别,具有较好的代表性。标注方法为BIOE,B 表示实体开始,I 表示实体内部,E 表示实体结束,O 表示不是实体。
使用准确率P、召回率R和F1 分数来评价算法效果,具体公式如下:
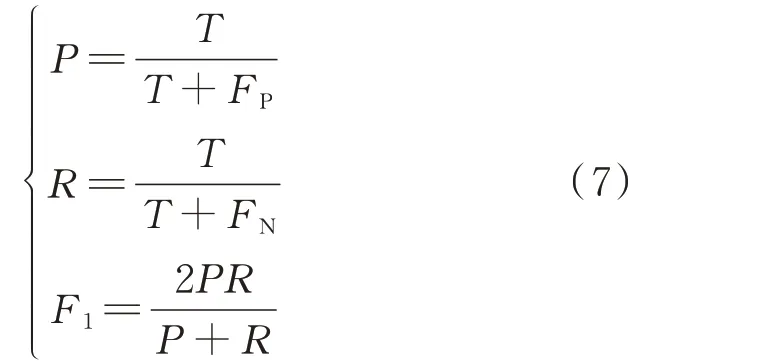
式中:T为正样本判为正的数量;
FP为正样本判为负的数量;
FN为负样本判为正的数量;
F1为F1 分数,是准确率P和召回率R的综合值,表示既希望较高的召回率,也希望较高的准确率。
2.2 实验方法
电力命名实体识别的效果与词向量工具的选择、文本特征的学习、模型构成有直接关系。因此,本文从以下几个方面验证方法的有效性。
1)不同文本向量对实体识别性能的影响
基于文本特征增强的电力命名实体识别方法,分别采用Word2vec、ELMo、BERT 获得中文电力文本的向量表达,测试不同文本向量对命名实体识别效果的影响。BiGRU 的学习率为0.01,隐节点数为150,Dropout 为0.5,迭代次数为100。实验采用5 折交叉验证,即将数据集随机划分为5 份,4 份用于模型训练,剩下的1 份用于测试,对结果取平均值。实验结果见表1。
由表1 可知,得益于文本向量的性能提升,命名实体识别的性能也得以提升。但随着文本向量的能力提升,也意味着计算、存储资源占用更多,需要结合电力业务的具体应用场景选择合适的词向量工具。
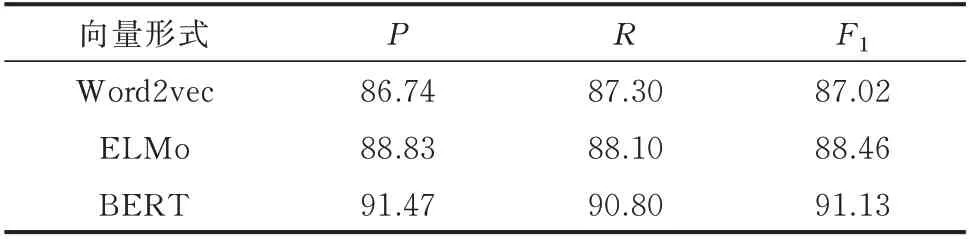
表1 不同文本向量的性能比较Table 1 Performance comparison of different text vectors
2)不同模型构成对实体识别性能的影响
基于同一词向量工具Word2vec,采用本文的基于预设词库的低粒度分词以及文本增强方法,分别测试BiLSTM-CRF、BiGRU-CRF、BiGRU-AM-CRF 3 种模型的实体识别效果,实验结果见表2。
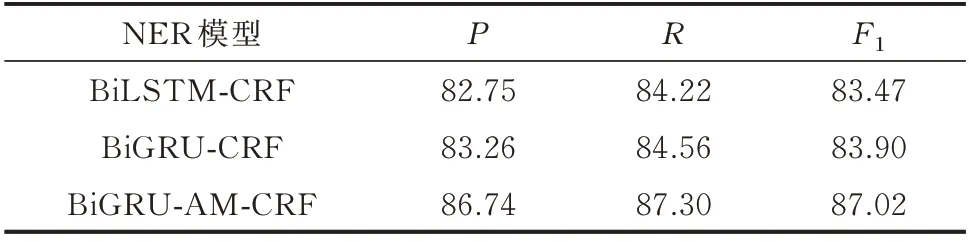
表2 不同NER 模型的性能比较Table 3 Performance comparison of different NER models
由表2 可知,基于本文的小样本量中文电力语料数据,BiLSTM 和BiGRU 性能接近,甚至BiGRU的准确率还略高一些。在此基础上,加入注意力机制后,识别效果有了较大提升。这也证明,词级BiGRU 重点完成文本局部特征(单词构造特征)学习,而NER 模型中的BiGRU 则着重于文本序列中单字和单词之间整体的上下文学习,并通过注意力机制加强了实体特征的权重分配,降低了单字的影响。相关方法的组合运用有良好的互补作用。
3)不同处理方法对实体识别性能的影响
基于同一文本向量Word2vec 表达,选取文献[5]、文献[22]、文献[25]和本文方法进行比较。其中,文献[5]、文献[22]和文献[25]均采用Jieba 分词工具完成分词,本文采用基于预设词库的低粒度分词。文献[5]在电力领域专用名词识别取得良好应用,其核心方法是BiLSTM-AM-CRF 模型。文献[22]是在BiLSTM-AM-CRF 基础上,采用CNN 学习单词的字符级特征,实现文本特征增强的代表性方法。文献[25]是基于Lattice-LSTM 模型,通过单字向量的LSTM 与单词向量的LSTM 级联来完成实体识别模型训练。本文是通过词级BiGRU 学习单词的内部构造特征,实现文本特征增强,同时采用BiGRU-AM-CRF 完成实体识别。
实验结果见表3。

表3 不同识别方法的性能比较Table 3 Performance comparison of different recognition methods
由表3 可知,基于相同的词向量工具,本文方法相对于文献[5]、文献[22]和文献[25]取得更好效果。文献[25]引入当前单字可能匹配到的全部单词,客观上带来更多的冗余信息,会影响实体特征识别的准确性。相比于文献[5],文献[22]通过引入单词的字符级特征,从而带来效果提升。和文献[22]相比,本文一方面采用基于预设词库的细粒度分词控制分词误差;
另一方面采用词级BiGRU 学习单词的内部构造特征,既包含单字内部组成和顺序特征,也结合了词长和词性特征,较CNN 获取的字符级特征更为丰富。
2.3 验证分析
以“定子双绕组内反馈串级调速高压电动机及调速控制装置”为实例,给出了文献[5]、文献[22]、文献[25]和本文方法的实验效果,如表4 所示,其中,红色字体表示识别出的电力命名实体。在本例中,“高压电动机”“调速控制装置”是电力设备及材料名称(power equipment and materials,PEM),“定子双绕组”“串级调速”是电力技术名称(electrical technologies,ET),均属于电力专有名词。同时,这些实体具有一定的模糊性。文献[5]的方法识别出“双绕组”“控制装置”“调速高压电动机”,但“定子双绕组”“调速控制装置”没有被完整识别,且未识别“串级调速”而是将“调速”与“高压电动机”识别在一起。类似地,采用文献[22]方法,“定子双绕组”“调速控制装置”等实体未能完整识别,且“串级调速”没有被识别成电力专有名词,而是识别为普通词。文献[25]方法考虑所有关联词,造成“组”与后面的“内反馈”“串级调速”识别到一起。本文方法正确识别出“定子双绕组”“串级调速”是电力技术实体,“高压电动机”“控制装置”为电力设备及材料实体,虽然未能将“调速控制装置”识别完整,但是整体而言,对电力专有名词的识别效果得到改善。

表4 不同方法的实施效果Table 4 Implement effects of different methods
本方法已在科研管理业务的技术能力地图中得以应用。技术能力地图是以科研管理系统中的科技项目和研究成果为基础数据构建的电力科技图谱,可以为量化评估科研能力、关联查找专家团队提供支撑[27]。技术能力地图的一个重要数据来源是研究成果,大量技术点隐含在专利、论文、软著、研究报告等科技文献中,人工检索困难,需要依赖准确的算法提取。
为在技术能力地图中柔性关联和展示挖掘到的技术点,设计了体系、项目、单位、人员、文献和技术六大图谱本体。知识图谱中的本体是指同一类实体及其属性和关系的集合。对于体系本体,技术体系内每层、每类的技术类别名称,就是体系实体,技术体系内的层数是实体属性;
对于项目本体,各类科技项目名称就是项目实体,项目层次(国家级、省部级、地市级等)等是实体属性;
对于单位本体,科研项目的执行机构就是单位实体,单位性质(企业、高校、院所)作为单位实体属性;
对于人员本体,科研项目的负责人或核心骨干就是人员实体,职称、职位作为实体属性;
对于文献本体,科研项目产出的专利、软著、论文、研究报告等为文献实体,文献类别作为文献实体的属性;
对于技术本体,指科技文献中描述的技术点,比如人工智能、量子加密、5G 通信等。对于体系、项目、单位、人员、文献5 类本体,依托现有科研管理信息系统的结构化数据库,从中抽取相应的实体和属性数据加入知识图谱中。对于技术类本体,采用本文方法从文献实体中抽取技术点,并自动建立技术实体与文献实体的关联。在此基础上,以科技项目实体为核心,向上关联体系实体,横向关联单位实体、人员实体和文献实体,向下关联技术实体,从而最终得到技术能力地图,在显性展示科研合作网络的同时,从电力技术实体的视角展示技术热点,如图4 所示。对于部分识别不准确的电力技术实体,一方面可以结合无监督的信息熵挖掘算法进行辅助校验,并通过词频予以过滤;
一方面通过开放分发的方式交由科研人员编辑纠正。

图4 技术能力地图Fig.4 Map of technology capability
电力领域的文本语料来源于电力设备管理、二次设备诊断、电网调控、资源中台元数据模型、电网营销等一线生产环境的运行数据及相关技术文献,具有专业性强、规模小的特点。电力实体识别可将这些业务场景中的文本信息转化成可用的知识,有利于电网专业知识的快速查询和智能检索。
本文提出一种文本特征增强的电力命名实体识别方法,通过预设先验词库和低粒度分词,合理利用中文单词蕴含的语义信息,降低分词误差带来的影响;
基于词级BiGRU 学习单词构造特征,结合词长、词性特征,与单词向量拼接后,实现文本特征增强;
在此基础上,通过BiGRU 完成文本序列的全局特征学习,采用注意力机制加强与实体特征相关的信息加权,降低单字对训练的干扰,最后通过CRF 完成文本标签的解码输出。
基于中文电力语料进行测试,以上方法的综合实施取得了良好效果,为相关研究提供了新的思路。但还需要获取更多的应用场景语料测试方法的普适性,引入更多的电力行业特征及字形、读音等特征,进一步探索模型训练参数对识别性能的影响。后续,可针对以上不足进一步开展相应的研究和测试,同时探索集成多类深度学习或机器学习方法实现工程应用中识别性能的综合提升。
采用本文方法训练的电力命名实体识别模型经封装后,以网络服务形式对外公开测试。在测试文本框界面中输入一段文字资料,点击测试按键,即返回识别的电力命名实体结果。相关脱敏的中文电力语料也同步公开,详见http://www.aeps-info.com:5014/。
本文研究得到国网电力科学研究院有限公司科技项目“知识图谱技术研究及在科技领域应用”资助,特此感谢!
猜你喜欢 单字分词语料 面向低资源神经机器翻译的回译方法厦门大学学报(自然科学版)(2021年4期)2021-06-22分词在英语教学中的妙用校园英语·月末(2021年13期)2021-03-15可比语料库构建与可比度计算研究综述电脑知识与技术(2019年23期)2019-11-03结巴分词在词云中的应用智富时代(2019年6期)2019-07-24结巴分词在词云中的应用智富时代(2019年6期)2019-07-24《汉字的特点与对外汉字教学》读后记北方文学(2019年5期)2019-03-15论计算机字库单字的著作权保护法制博览(2018年7期)2018-11-05“对仗不宜分解到单字”毋庸置疑——答顾绅先生“四点质疑”中华诗词(2016年11期)2016-07-21国内外语用学实证研究比较:语料类型与收集方法外语教学理论与实践(2014年2期)2014-06-21《通鉴释文》所反映的宋代单字音特殊变化西南学林(2013年1期)2013-11-22栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: