基于全词BERT的集成用户画像方法
于伟杰,杨文忠,任秋如
(新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
近年来中国互联网高速发展,APP和网站数量都有了前所未有的提升,智能手机的快速普及使得普通人都可以通过手机在网络上表达自己的思想,让生产内容从原先的阳春白雪走向了下里巴人,每个人都是内容的生产者,因此生产了大量数据,信息爆炸的时代就此来临.但是从海量的爆炸信息中挖掘数据之间隐藏的关系,是许多科研人员密切关心的问题,探索过程中诞生了许多知名技术,用户画像便是其中的佼佼者.交互设计之父曾经说过:“用户画像是真实用户的虚拟表示,是基于用户的真实数据挖掘和构建的目标用户模型.”[1]根据目标用户画像,企业能够精准营销、精准投放;
设计师能够设计和优化产品;
分析师能够丰富和充实行业报告.[2-3]
构建用户画像模型的方法中,目前主流的方法是给用户贴标签,用具体的属性词来描述用户属性和兴趣爱好,这时的关键词可以采用多种方式来生成,可以是机器学习模型、神经网络模型和规则分析.例如,Cha等[4]在计算影响力的方式上进行了改进,改进的具体内容是将更多的内容加入到影响力因素上,比如推特用户的用户关注数、被转发和点赞的次数,从而分析用户的行为,得出用户的属性和兴趣爱好.经过对比实验证明,与单纯使用行为特征的单一特征算法相比,引入更多特征Cha的实验结果更好.但是由于用户行为的复杂性和多样性,再加上推特中含有大量的杂质信息,因此模型效果还有改进的空间.费鹏等[5]在之前研究的基础上,融合多视角,提出了新的建模框架,该框架使用两种方式对用户进行建模,从而构建了多源特征,在将数据维度提高后,为了避免“维度诅咒”问题,引入了双层Xgboost(Extremegradientboosting)的多视角模型,从而较好地解决了问题.由于数据的不连贯性,尽管该方法从多角度构建了多元特征,但是没有使用数据中的深层语义信息.神经网络的大热,使得NLP相关人员也开始使用神经网络提取数据中的深层语义信息.Collobert等[6-7]是最早开始研究将CNN引入到NLP任务中的,经过测试,实验结果有了明显提升,许多学者接连在文档分类任务中使用CNN[8-10].例如李恒超等[11]就在建模过程中引入了CNN的算法,从而提出新的框架.框架分为二级:在第一级框架中,引入浅层神经网络模型与机器学习算法对文本数据进行处理;
在第二级框架中,对于多个Xgboost模型引入Stacking进行融合.实验结果数据显示,该框架的实验结果相较对比实验有明显地提升,但是缺点也很明显,就是文章使用的是浅层神经网络,无法获取文本的深层语义信息,对于具有强语义关联的文本实验结果较差.对此,陈巧红等[12]在分析了缺点之后,提出了一种基于集成学习框架的用户画像方法.该方法开始探索对不同长度的用户文本采用机器学习和深度学习的算法,取得了良好的效果;
但是语义编码模块使用的是基础的BERT方法,文字按照字划分,失去中文独特的词语特性.
本文对文献[12]提出的集成学习框架进行改善和优化,提出了一种基于全词BERT的集成用户画像方法,提升其泛化和分类能力.对不同特征采用不同分类器进行处理,用改进的集成算法决定集成的权重参数,取得最终的输出结果.
1.1 整体流程
本文提出了一种基于全词BERT的集成用户画像方法来给用户“贴标签”.如图1所示,将用户的不同形式文本输入模型后,多个分类器会对文本进行分类,使用改进后的集成算法确定各分类器的权重,最后投票确定结果.具体流程如下:
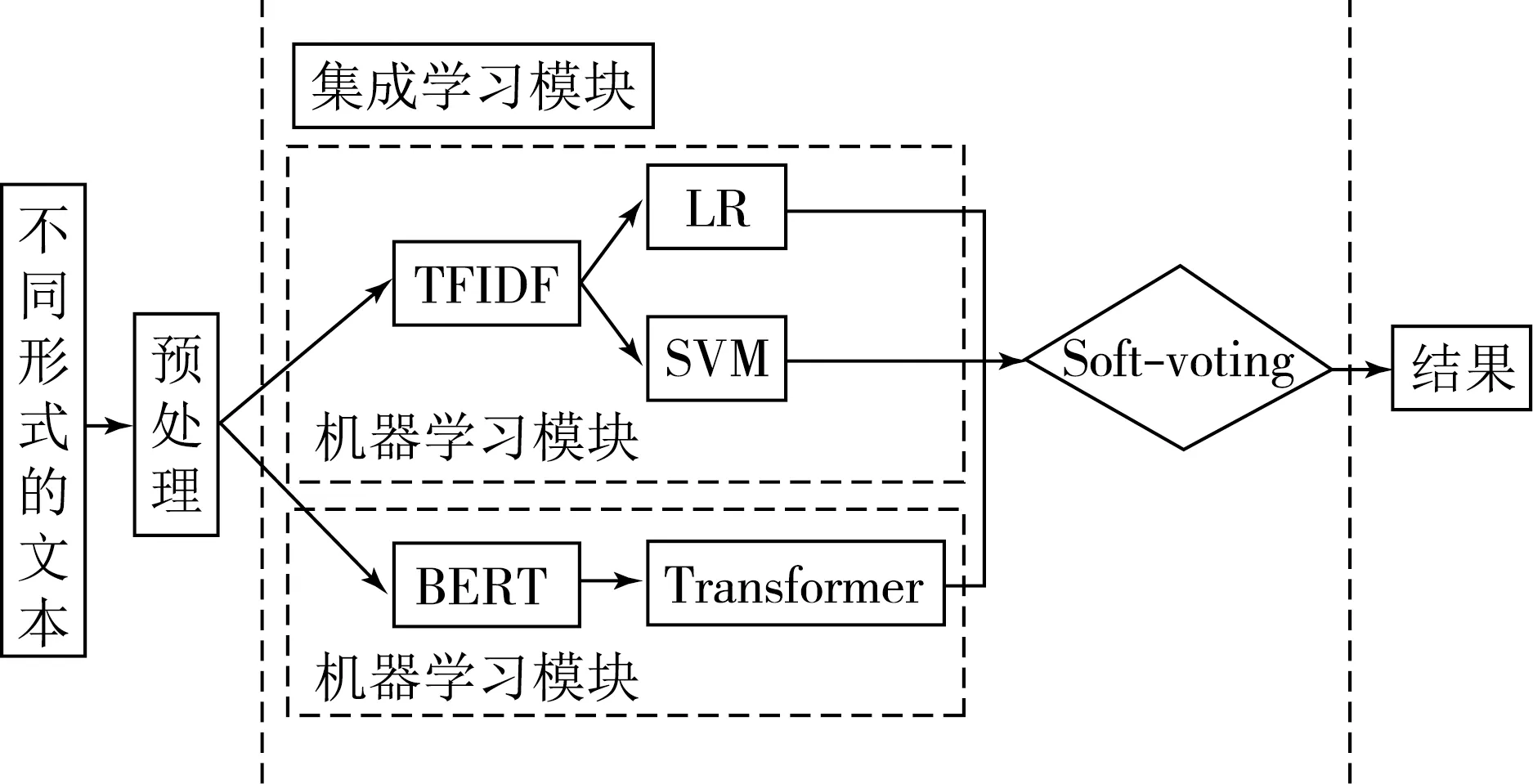
图1 集成算法结构图
步骤1 输入不同形式的文本数据集并进行预处理.
步骤2 对预处理后的数据集,一方面采用TF-IDF提取用户用词习惯特征,将特征分别输入LR模型、SVM模型;
另一方面,使用全词BERT模型挖掘文本的深层语义信息.
步骤3 根据各个分类器的预测结果输入到改进的集成学习加权投票分类器中,得出最终分类结果.
1.2 用户用词特征构建整体流程
TFIDF[13]作为文本特征提取方法,核心是评估数据集中每个字词的重要性.该方法认为字词的重要性与文档中出现的次数和语料库中出现的频率有关,具体来说,跟前者成正比,而跟后者成反比.[14]
TFIDF=TF×IDF#.
(1)
TF是单词termfrequency的缩写,单词的汉语解释是词频,具体来说就是词汇在文档出现的次数,IDF是单词inversedocumentfrequency的缩写,汉语解释的意思是逆文档频率,主要作用是进行文档的区分,计算流程是统计具有词汇t的文档数量,数量与IDF的值成反比,而IDF的值代表了辨识性和类别区分能力.
TFIDF的计算公式为
(2)
其中:TF(w,d)代表词汇w在文档d中出现的次数,N代表数据集中的文档个数,DF(W)代表整个数据集中包含词汇w的文档个数.
1.2 分类算法对比
本文集成学习模块使用了两种分类算法,两种分类算法的原理及缺点见表1.

表1 两种分类算法对比
1.3 Transformer的语义编码
Transformer[15]是在encoder-decoder框架上做的改进,结构分解后主要包括编码和解码两大部分.编码部分中编码器的数量可以根据具体实验中数据集的大小调整,但是结构必须相同,且不共享参数.解码部分的解码器数量也是可以调整的,但必须与编码器的数量相等.两者结构比较相似,相同的部分是都有自注意力层和前馈神经网络层,但是不同之处也有,比如相较于编码器,解码器多了一层编码-解码注意力层,工作流程是先对输入序列进行处理,生成向量列表,向量列表中包含位置信息,然后用自注意力层对向量进行处理,处理后每个向量中的每个句子的每个字都包含该句的全部信息,然后向量就可以传给前馈神经网络层,一个编码器的流程就完成了,经过全部编码器处理完毕后,会将其输出到解码器中,解码阶段重复进行处理,直到到达一个特殊的终止符号完成.由于在编码和解码的过程中大量使用了self-attention,能够实现快速并行,相较于原先使用RNN作为特征提取器,训练速度有了较大提升,并且可以扩展神经网络的深度,从而充分利用DNN模型的特性,提升模型训练的准确率.编码器中的TransformerBlock如图2所示.

图2 Transformer编码单元结构图
1.4 全词BERT
由于中文的一词多义性,因此目前有大量的多义词在日常和书写的中文数据语料中被广泛使用.如“我今天把黑色墨水用完了,需要买一瓶新的”与“他肚子里有很多墨水,出版了许多优秀为散文和诗词”.在这两个句子中,“墨水”一词虽然都是同一个,但是深层语义却不同,而且传统的词向量方法是无法表示词的深层语义,也无法表示词的多义性,因此本文改用的全词BERT[16]模型,从而能够较好地解决词的多义性问题.
BERT模型训练过程如图3所示,图3中Ei是指的单个字或词,Trm代表上述的Transformer编码器,Ti指的是最终计算得出的隐藏层.根据之前Transformer的原理简述,Transformer可以得到输入的句子序列中的每一个字,并且由于采用了不同的训练方式,即双向,因此在训练出的向量中,任意一个字向量都包含了该句的信息.

图3 BERT训练过程图
不过由于原先发布的BERT-base(Chinese)是由谷歌进行训练的,因此没有考虑中文特有的需要,中文不是以词为粒度,而是以字为粒度进行切分,因此对中文的任务效果还能有进一步的提升.因此在2019年5月31日,针对原先训练存在的不足,谷歌对BERT进行了改进,发布了BERT的升级版本技术whole word masking(wwm),该技术对训练样本的生成方式进行了改动,将字为粒度改成以词为粒度.在采用wwm技术之后,经实验证明后,全词mask比字粒度的BERT在中文任务上有更好的表现[17].
在本文使用的预处理模型是哈尔滨工业大学公布的基于全词遮罩(whole word masking)技术的中文与训练模型BERT-wwm-ext[18].
1.5 基于集成学习的加权投票算法
为了发挥使用关键词构建特征的两种分类方法的和提取语义深层信息的全词BERT的优势并进一步提高分类的准确性,通过对分类算法的对比,在得到算法的分类结果后,采用多分类器的集合进行多数表决.投票主要分为硬投票和软投票,硬投票就是最简单的少数服从多数在投票算法中的应用.而软投票,也被称为加权投票算法,通过输入权重为不同的分类器设置不同的权重,从而区分不同分类器的重要性.而权重的大小基本取决于每个基分类器的正确率,得到每个类的加权平均值之后,选择值最大作为分类结果[19].
伪代码如下:
输入:训练集D={(x1,y1),(x2,y2),…,(xm,ym)};

基学习器L1,L2,…,L4;
过程:Step2:for 1,2,…,4 do,
Step3:ht=Lt(x),
Step:end for;
Step6:H(x)=C;

1.6 基于梯度上升算法的权重选择
梯度上升算法是一种优化算法,与梯度下降算法相反,该算法优化的目的是求目标最大值,不过与梯度下降的许多流程是相似的,比如说优化的路线仍然是函数的梯度方向,只不过是把更新中的减号变成了加号.软投票作为一种传统的加权投票算法,虽然相较硬投票的少数服从多数方法考虑了每个分类器的权重,但是具体权重的计算方法仍有改善空间.因此在本文中,对权重选择方法进行了改进,使用各基分类器的5次交叉验证的正确率(ACC)结果组成训练集,为梯度上升算法的输入,将步长设置为0.001,可以快速得到各基分类器加权投票的权重.

θi的更新公式为
其中α为步长.
梯度上升的伪代码:
输入:多分类器输出结果集D={(x1,y1),(x2,y2),…,(xm,ym)};
过程:step1:初始化所有θ=1,α=0.001,
Step2:for 1,2,…,mdo,
Step6:end for;
输出:θi.
2.1 数据集
本文实验(1)采用的是第七届CCF大数据与计算智能大赛中有关搜狗用户画像比赛的数据,数据主体部分是用户查询数据;
实验(2)采用的是2016smp_cup微博用户画像大赛提供的数据,数据主体部分是微博内容.由于这两个数据集的数据较为不平衡,使用爬虫数据进行补充,同时采用人工对数据进行了干预,让每个种类的数据的数量为10 000.为了实验结果具有对比性,采用相同的分类标签,即用户的性别、年龄.实验数据举例见表2.

表2 实验数据举例
2.2 衡量指标
在本文的实验数据中采用性别、年龄这两个标签来进行结果验证,性别对应的分类是二分类,而年龄对应的分类是六分类.其中对年龄标签采取数据分享技术[20],含义是将年龄分段,以段作为年龄分类的类别.最后用准确率对结果好坏进行判断,准确率来源于混淆矩阵,见表3.

表3 分类结果混淆矩阵
准确率表示预测该类别正确的数量占总样本数目的比例,公式为
(4)
2.3 结果分析
为了验证所提出方法的有效性,本文采用消融实验进行验证,即分别使用了逻辑回归、支持向量机、全词BERT模型和本文方法进行对比实验.
在实验过程中,为了选择最佳参数,使用控制变量法进行参数选择,控制变量法的做法是在选择最优参数的过程中,控制其他所有参数保持不变.传统机器学习方法采取5次交叉验证来保持结果的准确性.具体参数选择见表4.

表4 两上实验最佳参数
通过修改后的集成算法对算法LR、SVM和全词BERT集成,权重参数分别为0.184,0.070和0.746.
模型参数取不同的值会得到不同的实验结果,在实验的过程中,均选取最佳参数进行实验,实验(1)结果如表5所示,实验(2)结果如表6所示.

表5 实验(1)结果 %

表6 实验(2)结果 %
表5显示的是在以用户查询词为主要文本的数据集上,本文方法和其他分类方法的比较.分析实验结果,可以得出当数据集的主要内容是用户查询词时,本文方法与其他分类方法的准确率差距不是很大,对此重新分析数据集,推测可能是数据集中文本的内容是没有关联的查询词,查询词是没有规律的顺序,并且词语前后语义关联性很小,因此神经网络挖掘与分析文本内部的深层语义信息的优点无法发挥,不仅不会获取到更多有用的语义信息,甚至会因为其自身深层的网络结构让过拟合现象更容易发生.
表6显示了在以微博用户文本数据为主要文本的数据集上本文方法和其他分类方法的比较.从实验结果的对比中可以得出,当数据集的主要内容是具有上下文联系和一定语义逻辑的文本时,全词BERT模型的效果更好,对数据分析之后,推测是由于数据集中的微博文本相对于用户查询词的数据集,微博文本作为连续的语义文本,语句之间有明显的连贯性并且词语的多义性开始影响对句子的理解,而本文其他机器学习分类方法使用的用户用词特征,明显对时序性和深层语义的学习有限.但是在引入全词BERT模型后,实验的分类准确率确实有了较大提升,说明全词BERT模型引入是有效果的,全词BERT模型确实能够充分挖掘文本的时序性和深层语义关联性.
本文从查询词和微博文本两个数据集出发,经实验发现通过改进的集成学习投票机制能够结合不同算法的优点,提高了泛用性,能够适应不同形式的文本.表5和6的数据证明了本文方法确实效果好于单一的方法.
综上可知,本文提出的基于全词BERT的集成用户画像方法较好地解决了本文提出的问题,且效果较好.
2.4 与其他方法的比较
将论文公开代码中的数据集统一换成本文实验的数据集,参数选择默认参数,各种方法对比结果见表7和8.结果显示,本文方法在准确率上有较大提升.综上所述,本文方法在用户画像的分类上优于文献[11-12]的方法.表7为使用实验(1)的数据结果,表8为使用实验(2)的数据结果.

表7 在用户查询词的对比实验 %

表8 在微博文本的对比实验 %
本文提出了一个基于全词BERT的集成用户画像方法.该方法采用不同的分类器处理不同的特征,使用梯度上升决定软投票的权重,从而提升了泛化力和准确率.
本文虽然使用多用特征和分类器对用户画像建模,但是现在的主流数据已经是多模态数据,特别是短视频的流行,对用户画像建模产生了较大冲击,因此模型下一步的改进就是引入多模态数据,让用户画像的属性更加全面和准确.
猜你喜欢 全词分类器分类 分类算一算数学小灵通(1-2年级)(2021年4期)2021-06-09分类讨论求坐标中学生数理化·七年级数学人教版(2019年4期)2019-05-20不吹不黑党的生活(黑龙江)(2018年9期)2018-10-17数据分析中的分类讨论中学生数理化·七年级数学人教版(2018年6期)2018-06-26教你一招:数的分类初中生世界·七年级(2017年9期)2017-10-13基于差异性测度的遥感自适应分类器选择电子技术与软件工程(2017年14期)2017-09-08基于实例的强分类器快速集成方法计算机应用(2017年4期)2017-06-27基于层次化分类器的遥感图像飞机目标检测航天返回与遥感(2014年5期)2014-07-31一种基于置换的组合分类器剪枝方法中原工学院学报(2014年4期)2014-04-01梅花引•荆溪阻雪意林(2011年19期)2011-02-11栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: