基于一步张量学习的多视图子空间聚类
赵晓佳 徐婷婷 陈勇勇 徐 勇,2
人类借助于日渐先进的数据收集和信息技术,在不同领域中获取到不同类型的多数图数据,更加全面地挖掘出隐藏在数据中特征和结构信息[1-2].如图1(a) 视频监控通过采集不同时态下的图像,更加有助于理解行人的姿态、面部表情等行为动作;图1(b)采集不同视角下的汽车图片,有助于更加清晰地刻画车辆的全貌;图1(c) 表示的是一张人脸图像在Local Binary Pattern[3]、Gabor[4]、Histogram of Oriented Gradients[5]等描述下的特征表示.多视图数据可以反映出更加全面的信息,结合不同的应用场景,衍生出多种多视图学习应用,如多视图聚类[2,6-9],多视图半监督分类[10],多视图分类[11],多视图检索[12]等等.由于现实生活中的数据大多没有样本标签并且标签信息的获取十分复杂,在进行基于标签的分类操作时会耗费很大的人力、物力.另一方面,随着聚类算法的成熟,一些聚类算法[13-14]的性能逐渐逼近分类算法,多视图聚类引起了广泛关注.

图1 多视图数据示例Fig.1 Examples of multi-view data
现有的单视图聚类和多视图聚类算法的性能高度依赖于亲和度矩阵的质量,其核心是构造一个具有判别性的亲和度矩阵.对亲和度矩阵求解的方法大致划分为三大类,分别是基于图[15-16]、基于核[17-18]和基于子空间[7,19-23]的方法.例如,Liang 等[15]提出了同时对视图间的一致性和差异性进行建模的图聚类方法;Wang 等[16]提出了同时学习数据相似度矩阵和聚类结构的聚类方法.然而基于图的聚类方法是根据原始数据的特征直接进行图的构建,容易受到噪声和异常值影响.为了处理非线性复杂数据的聚类问题,文献[17]通过使用核技巧将稀疏子空间聚类扩展到非线性流形;Yin 等[18]将对称正定矩阵嵌入到再生核希尔伯特空间中,有效地揭示了潜在的子空间结构.但是基于核的聚类方法的性能在很大程度上依赖于核函数的选择,而在实践中如何选择核函数仍是一个待探索的问题.为了提升鲁棒性,子空间聚类方法利用独立的两步骤去学习亲和度矩阵,即1) 根据原始数据的特征矩阵对其进行自表示,利用特定正则项求得自表示矩阵;2) 通过自表示矩阵固定得到亲和度矩阵,来描述未标记数据点之间的成对关系.例如,稀疏子空间聚类 (Sparse subspace clustering,SSC)[22]和低秩表示(Lowrank representation,LRR)[21]是两种最具代表性的子空间聚类算法.他们分别利用l1范数和核范数得到了稀疏和低秩的自表示矩阵.Gao 等[24]采用谱聚类的方式整合不同视图的子空间聚类结果以获得一致性的指示矩阵.
为了挖掘多视图特征的高阶相关性,Zhang 等[6]和Xie 等[7]相继提出将所有视图的自表示矩阵拼接成一个三阶张量,即包含了二维点对点的维度,同时囊括了一个新的视图维度.Chen 等[25],Zhang等[26]和Wu 等[27]均采用张量这一数据结构来处理多视图聚类的问题,并利用联合学习和张量低秩优化的思想以学习一个更具辨别性的亲和度矩阵.此类方法的核心是低秩张量分解技术.现有常见的张量分解技术为CANDECOMP/PARAFAC分解[28]、Tucker 分解[29]、张量奇异值分解(Tensor singular value decomposition,t-SVD)[30].其中基于t-SVD的张量核范数是张量多秩l1范数的最紧凸松弛,在低秩近似理论与应用中取得了优异性能.文献[2]采用基于t-SVD 的张量多秩最小化方法,隐式地过滤掉高维噪声.文献[31]采用了自适应近邻的方法,为每个数据点分配最佳近邻来学习相似性矩阵,以捕获数据的局部特征.但这些方法都基于根据某种运算,如指数法[32]、绝对对称化[6]、平方运算[33]等,利用自表示矩阵固定求解亲和度矩阵,即两者的求解过程独立进行,无法有效地挖掘两者间的高度相关性,不能获取更优的亲和度矩阵.
为了解决上述问题,本文提出了一种新颖的基于一步张量学习的多视图子空间聚类算法,它可以有效地降低噪声和异常值的影响并探究亲和度矩阵和表示张量之间的高度相关性,以获得更优的亲和度矩阵,进而得到更优的多视图聚类性能.本文的贡献总结如下:1) 针对多视图聚类问题,提出了一种基于一步张量学习的多视图子空间聚类算法,该算法通过学习一个鲁棒的低秩张量表示进行聚类,充分挖掘了数据的多模态信息,具有较高的鲁棒性与准确率.2) 与现有多视图聚类算法相比,该算法在一个统一框架下对表示张量与亲和度矩阵进行联合学习,相互促进.利用t-SVD 对表示张量进行高阶约束,减少噪声和异常值的影响.并采用自适应近邻法重建亲和度矩阵,以获得更加灵活的图用于多视图聚类.3) 该算法采用交替方向乘子法进行有效优化.在多个数据集上验证了所提出方法在解决多视图聚类问题上的优越性.
本节包括亲和度矩阵学习、低秩张量表示的多视图聚类和张量奇异值分解三个部分.在表1 中总结了本文所使用的主要符号和定义.

表1 符号与定义Table 1 Notations and definitions
1.1 亲和度矩阵学习
多视图子空间聚类方法的核心是求解一个具有较强辨别能力的亲和度矩阵,以更好地捕获多视图数据间的一致性与差异性[1].基于自表示的子空间聚类方法凭借其出色的性能,成为该研究领域的热门方向[21-22],其优化模型依赖于自表示特性,即属于同一线性子空间的样本可以相互线性表示[34].数据集X=[x1,···,xn] 表示维度为d的n个原始样本点,其自表示学习模型如下:


基于图学习的多视图聚类方法往往利用原始数据学习亲和度矩阵.即将数据点作为构建的图节点,它们之间的边代表两者之间的相似性[38],其基本模型如下:

其中,aij表示亲和度矩阵A中第 (i,j) 个元素,若数据点xi与xj的的距离越小,则aij的数值越大,两者的相似性也就越高.大量的文献[2,15-16]借助图学习的思想,大大提高了聚类性能.
1.2 低秩张量表示的多视图聚类
多视图聚类中,假设有由V个视图构成的多视图数据其中第v个视图的特征维度为dv.考虑到使用三维的表示张量可更好的探索不同视图的一致性与差异性,Zhang 等[6]和Xie等[7]提出了基于低秩张量表示的多视图子空间聚类模型:

Φ(·) 将所有视图的表示矩阵作为正面切片竖向合并为一个三阶表示张量Z∈Rn×n×V.由于不同视图的特征维度可能不同,但是样本数目为固定值,所以将特定于视图的误差矩阵进行垂直连接,以构造误差矩阵E.使用张量表示相当于在保持矩阵表示的基础上增添了不同视图间关系的新维度,进而可以探索多视图中更加全面的内部信息.
1.3 张量奇异值分解


图2 张量奇异值分解示例Fig.2 Examples of t-SVD
本文提出了基于一步张量学习的多视图子空间聚类方法(One-step tensor learning for multi-view subspace clustering,OTSC),其框架结构如图3 所示.OTSC 利用张量将不同视图的特征自表示信息进行统一建模,并使用t-SVD 对其进行低秩表示.采用自适应近邻方法进行重建亲和度矩阵,联合学习亲和度矩阵A与‘干净’的表示张量Z,其优化过程借助乘法器交替方向法.

图3 基于一步张量学习的多视图子空间聚类结构图Fig.3 The framework of the one-step tensor learning for multi-view subspace clustering (OTSC)
2.1 OTSC 模型框架
大量子空间聚类方法[14,26,35,39]中亲和度矩阵的学习往往脱离原始数据的特征信息进行分步求解,使得聚类结果只能达到次优解.在处理多视图聚类问题时,常采用基于多个特定于视图的表示矩阵寻求一个一致性的表示矩阵的方法[14,16,40],忽视了视图间的高阶信息.为解决以上问题,本方法采用基于图学习的聚类方法,利用张量将样本间的关系拓展到视图间的高阶关系,并充分挖掘亲和度矩阵与多视图原始数据之间的密切联系,来获取一个更具辨别能力的亲和度矩阵.由于原始数据易被噪声和异常值破坏[41],故对表示张量进行t-SVD 以获得一个去除噪声和异常值的‘干净’张量,并与亲和度矩阵进行联合学习.基于以上思想,将图学习模型(2)拓展到具有V个视图的多视图数据中,可得:


多视图聚类的本质是根据样本的相似度信息,将样本划分到不同的簇中[43].为了提高聚类算法的性能,获得一个更具区分性的亲和度矩阵,采用自适应近邻方法,以确保簇内样本点的相似性高,簇间差异性大的特性.基于自适应近邻的方法仅保留ai中数值最大的前K项[31],其余元素aij(j >k) 置为0,可保证同类中的样本点的相似度系数大于簇间的相似度系数.参数β的值由自适应近邻数目即K值决定,详见第2.2 节优化过程式(20b).
2.2 模型优化
对目标式(6)进行优化求解的过程,涉及多个变量求解的问题,为此采用交替方向乘子法对式(6) 进行优化.式(6)中变量Z与目标函数和两个约束条件耦合,增加了计算难度,为此引入一个辅助变量Y使其解耦为:

针对上式,构建增广拉格朗日函数,获得无约束目标函数计算公式如下:

借助增广拉格朗日公式将式(7)中的约束条件转换为式(8) 最小化问题.其中〈·,·〉代表矩阵的内积运算; Θ,Π和ρ分别表示拉格朗日乘子与惩罚参数.
对式(8)通过固定其他变量来交替求解各变量优化的子问题,以求得最优解.优化过程中首先通过t-SVD 学习更新变量Z,其次更新辅助变量Y;之后对噪声矩阵E和亲和度矩阵A同时更新;最后更新两个拉格朗日乘子 Θ,Π和惩罚参数ρ.详细子问题优化过程如下:
1)更新Z:固定式(8)中与Z无关变量,对Z第t+1 次迭代的优化问题可化为:

由于不同视图之间互不干扰,故上式中变量Yv是相互独立的,因此将上式等价转换为V个子问题,其中第v个视图的变量更新问题可写为:

式(11)对Yv是凸函数,因此对上式求关于Yv的导数并使其为0,求得Yv的如下封闭解:


亲和度矩阵反应了样本之间的相似性关系,直接决定了一个聚类算法的性能好坏.为了获得更灵活的相似度矩阵,确保类内样本点的相似度高于类间样本点的相似度,对其应用自适应近邻方法,仅保留A中前K项最大值的ai,以提高聚类的性能,如下式所示:
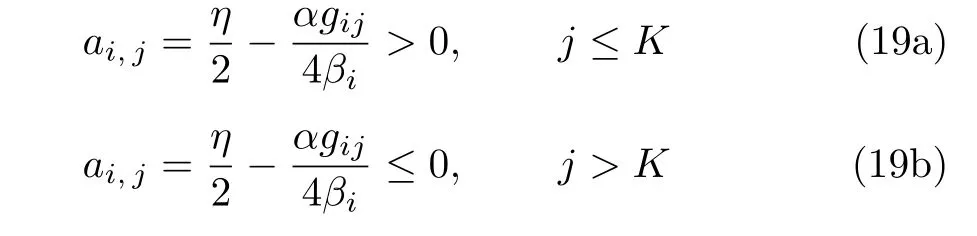

由上式可知,在式(6)中的参数β是由自适应近邻的数量K所决定.这意味着仅需在在式(6)中预先定义参数α,γ和近邻数量K即可进行算法的优化工作.
5)更新 Θ,Π和ρ:在 (t+1) 次迭代过程中,拉普拉斯乘子 Θ,Π和惩罚参数ρ的更新方式如下:

其中λ>1,ρmax代表ρ的最大值.本方法可总结为算法1,通过对式(6)的优化,获得亲和度矩阵A的最优解,之后在A上应用谱聚类算法,得到最终的聚类结果.
算法 1.OTSC 多视图子空间聚类的优化算法

2.3 时间复杂度分析
3.1 实验设计
数据集:为了验证算法的有效性, 在六个分别隶属于面部图像、新闻故事、手写数字和通用对象场景四种不同类别广泛使用的数据集上进行实验.
1) Extended YaleB:该数据集由耶鲁大学发布, 包含38 个人类对象在不同光线强度下的各64张图像. 在本实验中根据文献[6]只对前10 个不同对象进行验证, 构成了包含640 张面部图片的数据.
2) ORL:ORL 人脸数据集是由英国剑桥Olivetti 实验室所创建. 包含40 个人在不同的时间、光照、面部表情(睁眼/闭眼, 微笑/不微笑)和面部细节(戴眼镜/不戴眼镜)环境下采集的400 张图像.Extended YaleB 与ORL 数据集都属于面部图像类别, 对二者分别提取强度、LBP[3]和Gabor[4]三种特征作为多视图数据的不同视图.
3) 3Sources:该数据集是从BBC、路透社和卫报三种在线新闻收集的多视图文本数据集, 涵盖416 条不同的新闻报道. 数据集来自六类主题标签:商业、娱乐、健康、政治、体育、技术, 是具有三种特征的多视图数据.
4) BBCSport:属于新闻故事类数据集, 来自2004-2005 年BBC Sport 网站的五个主题领域的体育新闻文章, 常用作机器学习研究的基准. BBCSport 包含具有两种不同类型特征的544 个文档,构成V=2 的多视图数据.
5) UCI-Digits:数据集包含从荷兰公用事业地图集合中提取的手写数字(0 ~9)共10 类阿拉伯数字, 每类有200 张图像. 依据[16]提取了该数据集傅里叶系数、像素平均和形态特征三个特征作为多视图数据.
6) COIL-20:该数据集由哥伦比亚大学图像库发布. 含有20 个不同物体在360° 旋转中不同角度的各72 张成像. 与ExtendedYaleB、ORL 数据集相同采用1 024 维强度、3 304 维LBP、6 750 维Gabor 三个视图特征.
表2 详细总结了上述六个数据集的信息.

表 2 真实多视图数据集信息Table 2 Summary of all real-world multi-view databases
对比算法:本文提出的方法与以下12 种最先进聚类方法进行对比, 其中包括3 种单视图聚类(SVC)和9 种多视图聚类(MVC)方法. 为了和SVC方法进行对比, 在多视图数据的每个视图上分别采取SSC[22]、LRR[21]、RSS[42]三种单视图聚类方法, 并选取最好的聚类结果; 11 种流行的MVC 方法, 包括低秩和稀疏分解(RMSC)[40]、多样性诱导多视图子空间聚类(DiMSC)[44]、低秩张量约束的多视图子空间聚类(LT-MSC)[6]、自动权重的多视图学习(MLAN)[45]、多视图张量多秩最小化(t-SVD)[7]、基于图的多视图聚类(GMC)[16]、潜在的多视图子空间聚类(LMSC)[46]、张量积表示(SCMV-3DT)[39]、多视图子空间聚类中的低阶张量图学习(LRTG)[41]、加权张量核范数最小化(WTNNM)[47]和图正则化的张量和亲和度矩阵低秩表示的子空间聚类(GLTA)[25].
参数设置:模型中有四个参数α,β,γ与K, 其中α,β,γ分别表示局部流形、亲和度矩阵正则化项和噪声在模型中的贡献度,K为自适应近邻数目.由于式(6)中参数β可由参数α与K通过式(20b)求解得出, 因此模型中只需对参数α,γ,K进行参数选择. 实验中, 依据经验对参数α和γ从集合[0.001、0.005、0.01、0.05、0.1、0.2、0.4、0.5、1、2、5、10、50、100、500]中选择,K从[5, 15]的区间选择以寻求最优的聚类性能. 具体的, 针对七个多视图数据集的参数设置如表3 所示. 在对比实验中, 本文遵从对比算法相应文章中的参数设定, 对每个算法进行了10 次测试, 并记录了最优的参数下的平均结果和标准偏差.
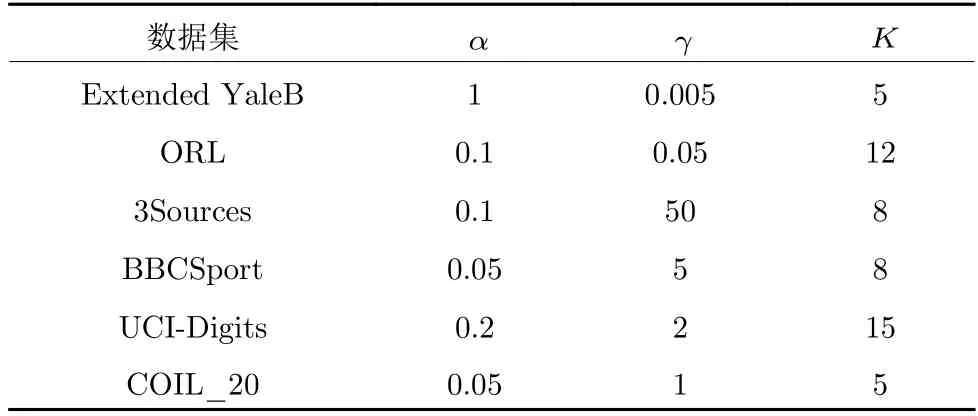
表3 参数设置Table 3 Parameter setting
评估指标:为了全面地验证本算法的性能, 采用准确性(ACC)、标准化互信息(NMI)、调整后的等级指数(AR)、F 分数、精确度和召回率六个流行的指标来评估聚类性能. 不同的指标侧重于聚类不同的属性, 但都满足其值越高, 聚类性能越好的特性. ACC 是评估聚类任务的常用度量指标, 定义为:

上式中,Li,Yi分别表示第i个样本的聚类标签和真实标签,δ((map(Li)=Yi) 表示正确聚类样本的个数.NMI 的具体数学定义为:

其中,H(·) 表示熵,I(·) 表示互信息,可表示为:I(L,Y)=H(L)+H(Y)-H(L,Y) 反应了L与Y之间的相关程度.AR、F 分数、精确度和召回率将聚类视为一系列决策,其相关定义的更多细节可参考文献[7].
3.2 实验结果
受文献[47]的启发,本文也考虑了利用加权张量核范数进行张量低秩优化,并用WOTSC 表示.实验结果如表4~表6 所示,加粗数字表示最优聚类结果,下划线的数据表示次优结果.通过观察实验结果,可以得出以下结论:1) 本文提出的OTSC及WOTSC 在大多数情形下都取得了最优值,或者次优解,彰显了本算法优异的聚类性能.2) 通过比较SVC和MVC 的聚类结果,可知大多数MVC 算法的性能高于SVC 的聚类结果,直接地展现出多视图聚类的优势.例如,在Extended YaleB 数据集上,WOTSC 比SVC 最优的RSS 算法的聚类性能在六个指标上分别提高了23.0%、15.6%、25.3%、22.7%、23.8%和21.6%.3) 与LRTG 方法进行对比,本方法在所有数据集上的聚类效果都优于LRTG.这是由于所提方法是通过t-SVD 对数据特征的表示张量进行低秩约束,以去除高维噪声和异常值.相比于塔克分解,t-SVD 更具鲁棒性与高效性.4) RMSC、LT-MSC、LMSC和t-SVD 都是基于低秩表示的多视图聚类方法,通过独立的两步求解亲和度矩阵,即亲和度矩阵的计算与表示张量的求解分步进行.通过与以上算法的对比,可得本文提出的方法通过联合学习表示张量和亲和度矩阵,可以更好地捕获数据中的底层低维结构.
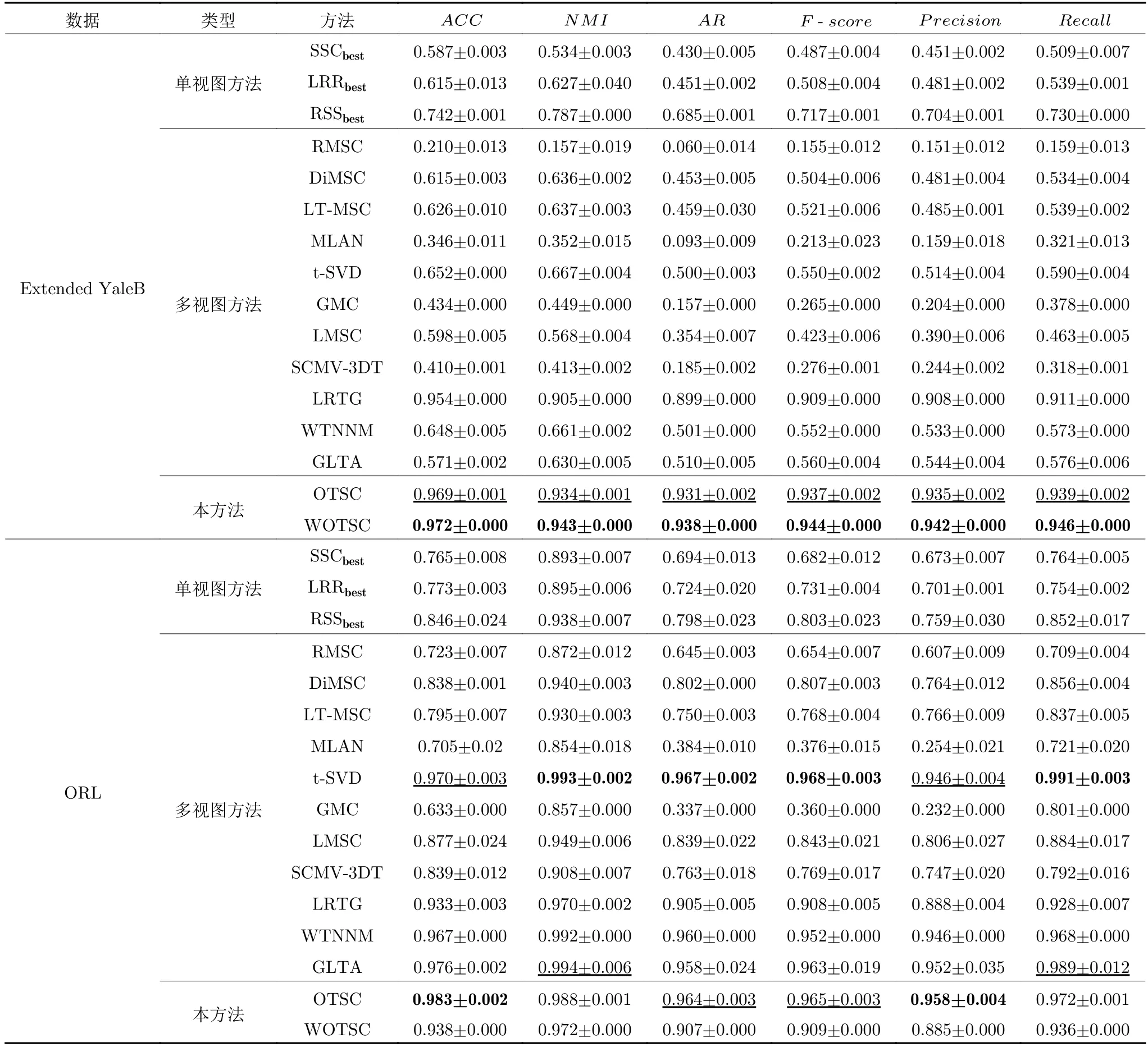
表4 数据集Extended YaleB、ORL 的聚类结果Table 4 Clustering results (mean ± standard deviation) on Extended YaleB and ORL

表5 数据集3Sources、UCI-Digits 的聚类结果Table 5 Clustering results (mean ± standard deviation) on 3Sources and UCI-Digits

表6 数据集BBCSport、COIL-20 的聚类结果Table 6 Clustering results (mean ± standard deviation) on BBCSport and COIL-20
3.3 模型分析
消融实验:为了探究联合优化模块对本算法的性能影响,探索‘一步化’学习表示张量与亲和度矩阵的有效性,本节对该模块进行消融测试.分别在Extended YaleB、COIL-20、3Sources、UCI-Digits 四个数据集上进行实验,OTSCA和OTSCZ分别表示依据经过联合优化的亲和度矩阵、表示张量以进行聚类的方法.实验结果如图4 所示,可观测出,OTSCA的ACC与NMI的值都高于OTSCZ,其中在Extended YaleB 数据集上尤为明显,彰显了联合优化模块的高效性与探索亲和度矩阵与表示张量的高阶相关性的积极作用.参数选择:为了验证参数选择对OTSC 模型的影响,本文在ORL 数据集上进行了参数α和γ在[0.001、0.005、0.01、0.05、0.1、0.2、0.4、0.5、1、2、5、10、50、100、500]的集合上遍历的实验.结果如图5 所示,可看出本算法在该数据集上当γ取自区间[0.05,0.5],α取自区间[0.00,1]时,有较好的性能 (ACC和NMI取得较高的值).此外,本节还探索了参数自适应近邻数目K对聚类结果准确率的影响.结果如图6 所示,显示出ORL 数据集在参数K取值由5 到9 时ACC为递增变化,并在K=9 时取得最大值.

图4 OTSC 性能的消融实验Fig.4 Ablation experiment of OTSC performance

图5 根据 A CC和 N MI 调整数据集ORL 参数 α 与γFig.5 Parameters tuning in terms of A CC and N MI on ORL

图6 参数 K 对数据集ORL 的 A CC 影响Fig.6 The effect of parameter K on the A CC of ORL.
3.4 模型收敛性
本算法采用交替方向乘子法进行多个变量的更新,具有较快的收敛速度.图7 显示了OTSC 在数据集BBCSport、ExtendedYaleB 上准确率、停止标准与迭代次数的关系.可观测出,算法的残差在5 次迭代后趋于稳定,并且准确率也达到峰值而趋于稳定,都反应出本模型的优化算法的高效收敛性.
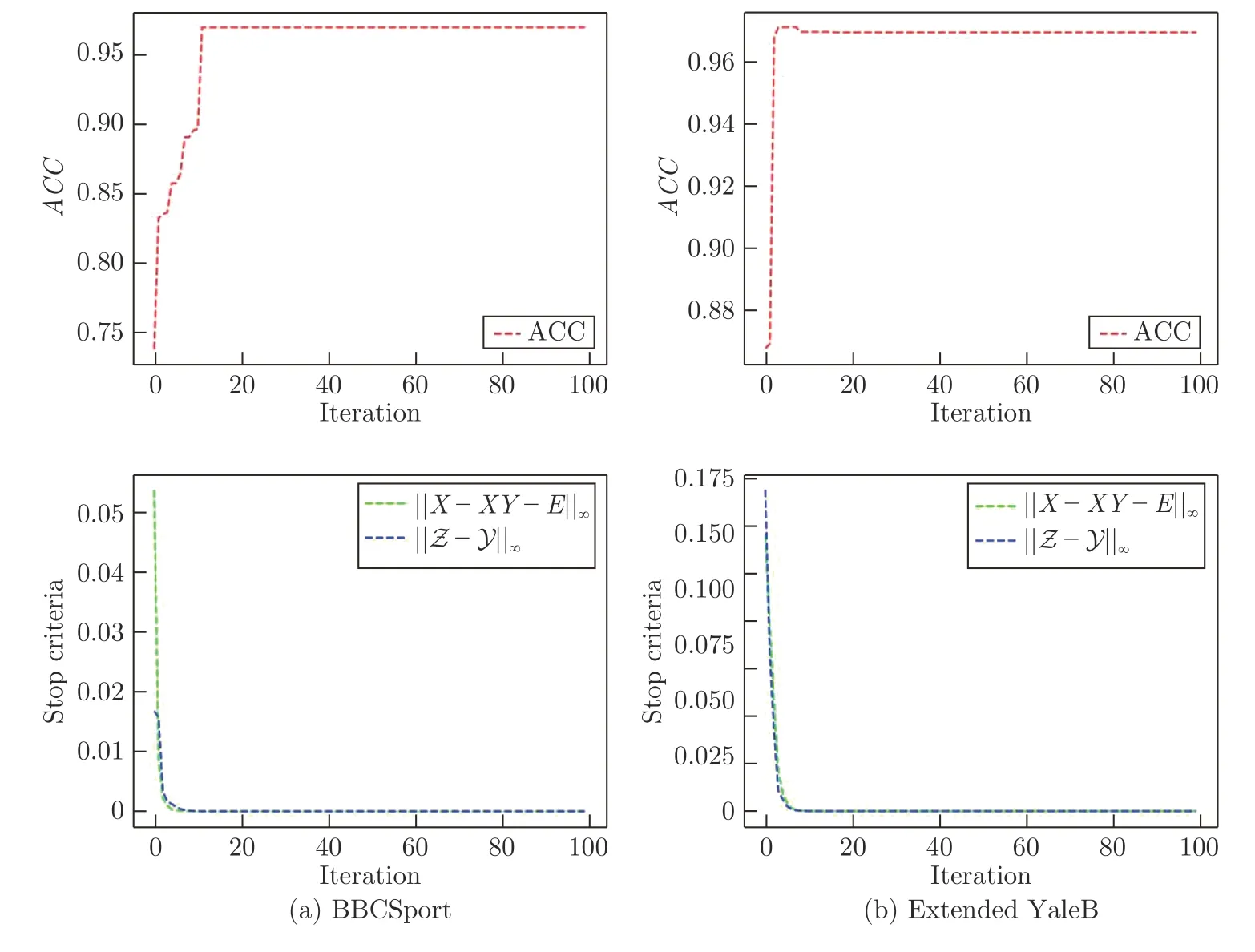
图7 收敛性曲线 ((a) BBCSport;(b) Extended YaleB)Fig.7 The convergence curves and ACC versus iterations on ((a) BBCSport;(b) Extended YaleB)
针对多视图聚类两步化求解亲和度矩阵、如何探索多视图之间的高阶相关性的问题,本文提出了一种基于一步张量学习的多视图子空间聚类方法.本方法借助图学习的思想,利用张量三维数据结构的属性来充分挖掘多视图数据的底层低维结构.具体地,本算法将特定于视图的表示矩阵拼接为三维张量以探索数据间高阶相关性,并采用t-SVD(如式(4)所示)低秩约束以寻求一个‘干净’的表示张量.通过引入‘一步化’联合学习框架,有效地实现表示张量和亲和度矩阵的共同优化,克服了对亲和度矩阵固定求解的问题.此外,还采用自适应最近邻方案,共同学习一个鲁棒的低秩张量图.由于该算法涉及多个优化变量,故采取交替方向乘子法进行交替优化.在六个多视图数据集上的实验表明本方法的有效性和鲁棒性.在后续工作中,考虑将‘一步化’联合求解的方法拓展到深度学习中,借助卷积神经网络来学习更具判别性的亲和度矩阵.
猜你喜欢张量视图聚类偶数阶张量core逆的性质和应用数学物理学报(2021年1期)2021-03-29四元数张量方程A*NX=B 的通解五邑大学学报(自然科学版)(2020年4期)2020-12-09一类结构张量方程解集的非空紧性杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09基于K-means聚类的车-地无线通信场强研究铁道通信信号(2019年6期)2019-10-085.3 视图与投影中学生数理化·中考版(2017年6期)2017-11-09视图非公有制企业党建(2017年10期)2017-11-03Y—20重型运输机多视图现代兵器(2017年4期)2017-06-02SA2型76毫米车载高炮多视图现代兵器(2017年4期)2017-06-02基于高斯混合聚类的阵列干涉SAR三维成像雷达学报(2017年6期)2017-03-26基于Spark平台的K-means聚类算法改进及并行化实现互联网天地(2016年1期)2016-05-04栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: