基于Attention模型的法律文书生成研究
徐 惠,苏 同,俞鹏飞,江全胜,朱咸军2,,4*
(1.南京航空航天大学,江苏 南京 210016;
2.金陵科技学院,江苏 南京 211169;
3.东部战区总医院,江苏 南京 210002;
4.江苏省信息分析工程研究中心,江苏 南京 211169)
当前“互联网+法律”的模式中,法律相关信息种类繁多,信息量大,加大了相关从业人员法律文书写作的难度。法律文书是日常生活中一切涉及法律内容的文书,如:诉讼法律文书、合同、协议等。由一个案件到一个法律文书的生成,抛去法律文书本身固定的模板以外,文书内容信息主要表达的是案件信息。非从业人员撰写的法律文书一般具有自然性、口语性,缺乏了法律化、规范化。因此,可以将自然语言转化成规范法律文书的过程认为是一种“翻译”的过程,是一个序列到另一个序列的问题,即序列模型(Seq2Seq)[1]。
LSTM(Long Short-Term Memory)[2]是一种特殊的循环神经网络(Recurrent Neural Network,RNN)[2],它在训练中会随着训练时间加长以及网络层数增多,很容易出现梯度爆炸或者梯度消失的问题,导致无法处理较长序列数据,从而无法获取长距离数据的信息,而LSTM能够较好地解决长序列依赖问题;
Encoder-Decoder[3]模型,即“编码-解码”模型,是一个主要解决Seq2Seq问题的框架;
Attention模型[4]是Encoder-Decoder模型的优化模型,打破在编解码时都依赖于内部一个固定长度向量的限制,能够更加准确地获得模型的输出。
本文将LSTM的Encoder-Decoder模型和Attention模型进行了综合,实现了法律文书的自动生成。
在处理自然语言的任务中,一个案件中案情信息转化成法律文书的处理过程分为两个步骤:
第一,识别筛选出案件中的案情信息(如案件的原被告信息、过程、内容、诉求等)。
第二,案情信息规范化。法律文书的书写具有严格的规范性,可以预先准备好对应法律文书类别的模板。
对一个普通案件性的描述语言进行特征提取、特征组合和规范化,并填充至法律文书的模板中。对于不同类型的案件描述,可能存在多个实体类别,产生的法律文书种类亦有所不同。
本文以婚姻类法律文书作为研究数据集,提出一种基于Encoder-Decoder模型和Attention模型的法律文书自动生成方法,并以婚姻纠纷类法律文书生成为例。
在自然语言叙述的一个法律案件中,不同人描述的习惯、方法、顺序都是不唯一的,具有多样性。这也就导致一个案件描述的机器可读性很差,需要对其进行一些预处理操作,进一步精简案件描述,便于找出其中的关键信息。
数据样本中不可避免地会有一些停用词(如:“的”“啊”等)。这些词的存在,会使接下来的模型训练和预测效果不佳,可以使用一个停用词集来去除文本中的停用词。
2.1 数据分词及向量化
对于去除停用词后的文本,重要信息之间的关系十分明显。接下来要对其进行分词操作,本文采用的是中文分词组件“Jieba”库。该组件有3种分词模式:精确模式、全模式和搜索引擎模式。如:“结婚以后我花的钱装修了房子”。停词处理和分词后“结婚”“以后”“我”“花钱”“装修”“房子”。
词性分析结果:[pair("结婚", "v"), pair("以后", "f"), pair("我", "r"), pair("花钱", "n"), pair("装修", "v"), pair("房子", "n")]。全文本采用TF-IDF算法得到关键词抽取结果["装修", "花钱", "结婚", "房子"]
分词结束后,使用词向量工具Word2vec[5]将词语向量化,并将词语、词性及词向量构成字典形成语料库。
2.2 语料库优化
构建一个动态语料库[6],在读取新的文本数据时,重复以上分词向量化以及词性分析等操作;
与原语料库形成多个文本语料库,并通过关键词抽取各文本的词汇特征向量,使用K-means算法对各文本的词汇特征向量进行聚类处理[7],获得多个文本的集合语料库,使得语料库可以不断学习新的词语,使文本生成效果更佳。
长短期记忆模型(LSTM)是一种特殊的递归神经网络模型(RNN),可以较好地解决梯度弥散的问题。在学习序列数据的长期规律时,能很好地处理序列内部的长期依赖关系。在自然语言处理方面,用LSTM模型提取文本的语义语法信息,完成各种(如文本分类、序列标注、文本匹配、翻译等)具体的任务。
3.1 Seq2Seq序列模型概述
Seq2Seq模型问题的特征是其输入的是一个序列,输出的也是一个序列,如:机器翻译、自动问答系统等。法律文书的生成实际上也是一种序列到序列生成的Seq2Seq问题。本文探究的过程以上述数据预处理中的例子——“结婚 以后 我 花钱 装修 房子”为例。
使用Encoder-Decoder(编码-解码)风格的神经网络模型以及注意力(Attention)模型来解决该问题并比较生成效果。
3.2 Encoder-Decoder模型
在Encoder中将一个长度模糊的数据序列转化成一个固定长度的数据向量,表达为原数据序列的语义向量;
Decoder将这个语义向量解码,产生一个长度可变的目标序列向量。而Encoder、Decoder的过程本质都是基于LSTM模型的,故整个模型的结构如图1所示。

图1 LSTM模型结构
参数含义如下:
{n1,n2,n3,n4,n5,n6}:分词结果的案件信息词向量输入ni。
{h1,h2,h3,h4,h5,h6}:Encoder阶段神经元在每个词向量输入后的隐藏层状态向量hi。
{t1,t2,t3,t4,t5,t6}:Decoder阶段神经元在每个预测词向量输出后的隐藏层状态向量ti。
{m1,m2,m3,m4,m5,m6}:词向量预测输入mi。
S:Encoder阶段结束后输出的句子的语义向量,包含了句子的语义信息。
Go:Decoder阶段的起始符号,表示开始执行解码操作。
Eos:Decoder阶段的结束符号,表示已完成解码。
算法过程如下:
如图1所示的模型实现过程,首先把经过预处理的案件信息向量化得到的Word Embedding[8](词嵌入)矩阵ni,作为输入,依次传入模型。在Encoder阶段,每个状态节点(图中虽然有多个节点,其实只是同一个神经元每个时间点下的状态)中要经历3个门操作来控制语义信息。
(1)遗忘门。该门决定放弃当前状态节点中一些信息,读取状态节点的前一个状态向量hi-1和ni,经过权重wf、偏移量bf以及sigmoid()函数,输出一个数值在0到1之间的向量矩阵fi,即:
fi=sigmoid(wf·[hi-1,ni]+bf)
(2)输入门。经过遗忘门,已经丢弃掉一些多余语义信息,此时通过输入门需要经历3步。
①决定状态节点中的更新信息,通过权重Wg,偏移量bg以及sigmoid()函数来得到更新向量矩阵gi;


gi=sigmoid(wg·[hi-1,ni]+bg)
(3)输出门。最后先要设置一个初始输出,同样用一个sigmoid()函数来获取初始输出向量矩阵oi;
然后用一个tanh()函数缩放遗忘门和输入门的信息向量ci,并与oi结合生成下一个状态节点的初始状态向量hi,同时也该状态节点的输出,即:
oi=sigmoid(wo·[hi-1,ni]+bo)
hi=oi*tanh(ci)
当Encoder阶段所有词向量的编码完成后,可以设置一个全连接层把每个状态的输出压缩成一个固定维度的语义向量S,也可以直接将最后一个状态的输出作为语义向量S。
将语义向量S输入Decoder阶段,即图1中的右半部分。由于Encoder阶 段和Decoder阶段都是基于LSTM模型的,其主要算法过程是一致的;
不同的是在Decoder阶段,当语义向量S输入时,需要一个触发向量Go,即开始解码的标志;
在解码结束时,需要一个终止向量Eos,即停止解码的标志。
在解码过程中的输出向量mj,可以先用一个SoftMax()函数产生一个关于法律语料库中的N个词向量的概率分布p(mk|m p(mk|m mk=arg max[p(mk|m 最后输出的{m1,m2,m3,m4,m5,m6}序列,根据语料库转化成{“婚后”,“原告”,“出资”,“装修”,“房屋”}为本例的生成结果,即实现了由“结婚以后我花钱装修房子”到“婚后原告出资装修房屋”的法律文本转化。 Attention模型实际上模拟的是人类的注意力行为,即人在观察一件事物时的关注点是不同的。在自然语言处理中,每句话中信息的重要程度并不是均衡的,是有一定的权重区分的; Attention模型的结构如图2所示。参数含义如下。 图2 Attention模型 {x1,x2,x3,x4,x5,x6}:经过attention层处理后存在“注意力”的非固定长度的语义向量,在Decoder阶段,可选择性地挑选其子集进行解码输出; aij:Encoder阶段中每一个隐藏层状态向量hi的权重值。由于Attention模型是以Encoder-Decoder模型为基础的,其编码解码的过程类似,主要添加了一个attention层,来分散注意力。 其attention层的算法过程如下。 在Encoder的基础上,对于隐藏层输出的每一个状态向量hi乘一个权重aij,求其加权平均,作为新的一个语义编码向量,即一个attention层的输出向量xi: 其中权重aij的计算需要Decoder阶段的隐藏层向量tj反馈,先用一个评分函数score(),来评价Encoder阶段hi和Decoder阶段tj的效果,记为eij,然后计算该评分与总评分中的比率就是该hi的权重,即: eij=score(hi,tj) SoftMax()函数可以产生一个关于之前制作的法律语料库中N个词的概率分布,其概率之和为1,即可在Decoder阶段每个状态向量输出时,预测出概率较高的转义词向量{mk},接下来输出预测词向量的过程参照Encoder-Decoder模型,最后同样能够产生语义类似的结果。 本文采用来自某法律案例网站的10 000条真实案件数据集,将数据集分为4个类别,即交通纠纷、债务纠纷、财产纠纷和婚姻纠纷。对数据进行清洗得到数据内容包括案件类型、原被告信息、案件描述和申诉请求。然后,对数据进一步去停用词、分词、人工标注等预处理工作。 本文实验的训练过程和预测过程的Encoder-Decoder模型(表格中简写为ED)和Attention模型,是使用基于Python语言的TensorFlow库构建的。在模型的训练过程中,进行了实验1:比较两种模型的训练效果(误差函数LOSS); 表1 2类模型下的训练效果 根据实验结果发现,学习率(LR_RATE)过大,在算法优化的前期会加速学习,使得模型更容易接近局部或全局最优解。但是在后期会有较大波动,甚至出现损失函数的值围绕最小值徘徊,波动很大,始终难以达到最优解; 图3 实验对比 图中的变化曲线显示,可以引入学习率随迭代次数的增加随衰减的机制,即在模型训练初期,会使用较大的学习率进行模型优化,随着迭代次数增加,学习率会逐渐进行减小,保证模型在训练后期不会有太大的波动,从而更加接近最优解。向量元素的保留率(KEEP_PROB),是各层向量元素的一个保留概率,当KEEP_PROB为0时,就意味着让所有的神经元都失活,而KEEP_PROB为1时,就是全部保留。在语义丰富的一个案件的描述语句中,其隐藏层的数量较多,为了更大程度地使语义向量S保留更多信息以及解码时减少语义缺少,同时由于数据集较大,防止过拟合,故可以将KEEP_PROB设置为一个0~1的小数,实验1中分别设置了0.4,0.5,0.6的保留率,除在学习率为1e-2的情况下,Attention发生了误差弥散直指梯度消失; 实验2:比较两种模型算法的生成效果; (1)实验室测试效果。选取100份新的样本数据作为测试用例,以模型预测输出的结果和人工标注的结果对比,做一个相似度分析(包含语义是否完全表达、语句连贯性、规范性),最后得出一个加权平均值作为生成效果,评估结果如表2所示。 表2 实验室测试效果 (2)实际用户测试效果。用户分为两类,普通大学生和职业律师,获取他们的采纳率,后台随机抽样调查,取平均结果作为生成效果。评估结果如表3所示。 表3 实际用户测试效果 从实验1—2结果数据来看,本文所提及的两种模型Encoder-Decoder模型和Attention模型,在法律文书生成训练过程的实验1中,Attention模型在整体上的收敛效果是优于Encoder-Decoder模型的,对于长文本的法律文书信息的处理具有更佳优越的效果; 本文提出的数据预处理方法和基于LSTM的两种模型来解决由案件信息到法律文书信息的过程问题,实现案件信息处理以高效获取有用信息,代替人对信息进行分析和综合。在实验过程中,案件信息根据用户描述的案件生成对应的案件词向量序列,将案情要素,输入模型进行学习,输出为生成对应案情描述的法律文书。同时, 对信息源的理解和文书生成需要一定的背景知识,可从语料库的学习中得到,并在实际应用中不断地自学习新的知识。从实验结果来看,Attention模型在训练过程以及生成效果方面的部分指标,都较优于普通的Encoder-Decoder模型,可以根据不同的案件完成对应法律文书的自动生成,且效果能使较大部分用户满意,可以使初步制作法律文书节省很多的时间和人力。3.3 Attention模型
通过对不同重要程度的词附上不同的权重,可以表达出更加合理的语义向量。

4.1 数据来源
4.2 算法效率分析
LOSS函数是通过将目标序列(target)作为输入传给Decoder端LSTM的每个阶段,做前一阶段预测输出和目标传入的差值产生的;
通过调整设置的超参以获得近似的最优解,超参分别为:模型训练的学习率(LR_RATE)、向量元素的保留率(KEEP_PROB),实验结果数据如表1所示。
甚至在训练“世代”(EPOCHS),即训练的迭代次数比较大的时候,会产生梯度爆炸或者弥散;
两种模型分别在相同保留率以及学习率为1e-2,1e-3及1e-4下的误差函数LOSS的变化曲线如图3所示。
其他情况下两种模型均可以收敛于一个的LOSS值,该保留率对变化效果不明显;
但明显可看出ttention模型的训练效果要优于Encoder-Decoder模型,误差loss能够更贴近最小值。4.3 算法生成效果评估分析
主要评价的是模型的预测效果。实验2为生成效果设置了以下几个指标:
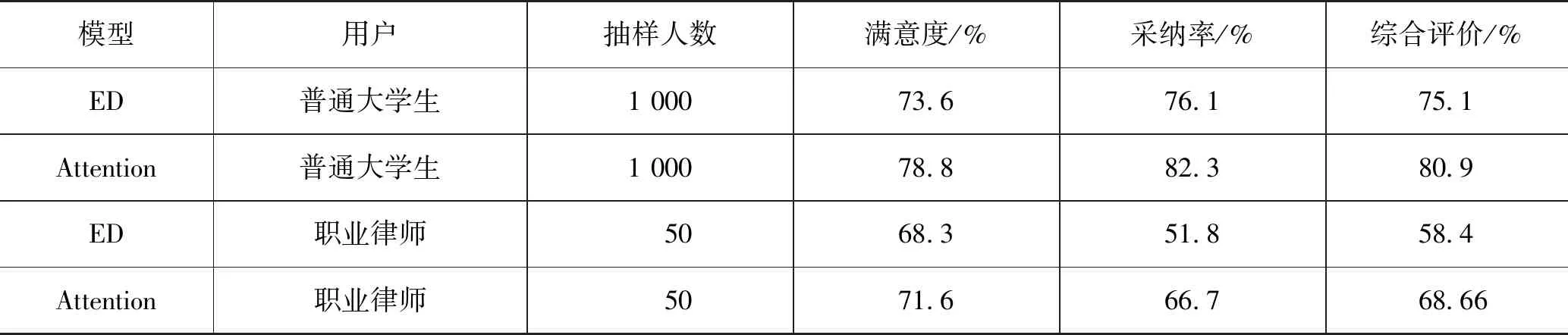
在预测生成法律文书评估的实验2中,不论是从实验室测试结果还是用户测试结果来看,对于法律文书的规范合理性,Attention模型的预测效果也是较好于Encoder-Decoder模型的。故Attention模型,在本实验中法律文书的生成准确性更佳,更加符合原法律案件,初步满足了一般用户对法律文书的需求。
栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: