结合AdaBoost和代价敏感的变压器故障诊断方法
刘云鹏, 和家慧, 许自强, 刘一瑾, 王 权, 杨 宁, 韩 帅
(1.河北省输变电设备安全防御重点实验室(华北电力大学),河北 保定 071003;
2.新能源电力系统国家重点实验室(华北电力大学), 北京 102206;
3.国网南京供电公司,江苏 南京 210019;
4.中国电力科学研究院有限公司, 北京 100192)
电力变压器对于电网安全稳定运行至关重要,随着变电站智能运维的发展,神经网络、支持向量机等智能算法已经在电力变压器故障诊断、状态评估等方面发挥了重要作用[1-3]。训练集样本足量且类别分布均衡是确保上述算法具有出色分类性能的重要前提,然而实际收集的数据集中正常样本与故障样本的比例十分悬殊。针对此类非均衡数据集,若采用上述智能算法,由于样本数量存在较大差异,当模型以最小化经验风险为训练目标时,分类模型将偏向于正常样本,导致故障样本的漏判率远高于正常样本[4]。因此,如何在非均衡数据的基础上提升模型的故障识别性能是设备故障诊断领域亟待解决的关键问题。
目前,针对非均衡数据的分类问题,业内学者提出的解决策略可分为数据和算法两个层面。数据层面主要通过调整样本数量实现样本类别分布均衡化[5,6]。其中,文献[5]通过随机复制少数类样本从而均衡样本集,但增加了模型过拟合的风险。为此,文献[6]中利用改进合成少数类过采样技术在部分少数类样本中合成新样本,间接改变和更新权重从而补偿偏斜分布。虽然这些方法一定程度上均衡了样本集,但未考虑数据的整体分布信息,因此往往对提升模型的分类性能较为有限[7]。算法层面主要通过优化算法结构,使其适应非均衡数据的学习及分类[8-10],在一定程度上避免了数据层面存在的问题。文献[8]中将故障误诊断代价作为权重合理融入诊断模型的最终投票结果,文献[9]中利用误分类代价最小取代误分类率最小为训练目标,文献[10]中通过代价函数调整错误权重向量。这为解决不平衡分类问题提供了一种有效思路,但这些方法定义的代价矩阵均由专家综合领域知识打分确定,故存在一定的主观性和不确定性。
作为动态集成算法,自适应算法(adaptive boosting,AdaBoost)具有较强的泛化能力和实用性,已广泛应用于数据预测、图像处理等多个领域[11,12]。综上,本文提出了一种结合AdaBoost和代价敏感的Adacost算法,用以解决样本集类别分布非均衡下变压器故障样本漏判率高的问题。该方法一方面在模型中加入主客观结合的代价敏感矩阵,保证模型的可信度和客观性;
另一方面在AdaBoost样本权重更新策略的基础上,引入代价敏感机制,基于代价函数更新样本权重,更好地考虑了少数类样本对整体分类准确率的影响。与此同时,本文以油中溶解气体无编码比值为模型的输入特征参量,分别建立决策树与AdaBoost分类器,以对比分析上述模型应用于变压器故障诊断的可行性和有效性。算例研究结果表明,相较于决策树和AdaBoost分类器,本文提出的Adacost算法能够有效提升非均衡数据集下诊断模型的故障识别性能。
1.1 AdaBoost分类模型
AdaBoost是一种迭代算法,通过迭代生成多个泛化性能较弱的基分类器,迭代完成后,聚合所有基分类器构成强分类器,从而提升模型的分类精度。具体算法流程如下:
令训练集S={(x1,y1),(x2,y3),…,(xm,ym)},其中xi为第i个样本的n维特征向量,yi是数据标签;
令迭代次数为T。
1)初始化训练样本权重
给定各训练样本一个权值,在第一轮迭代中各样本的权值平均分布。
(1)
式中:ω1i为第1轮迭代中第i个样本的权重;
初始化各样本的权重为1/m,m为总样本数。
2)第t轮迭代
①使用权重分布为Dt的样本集训练,根据xi的各个特征参量独立生成一个分类器htk(x)。
htk(x)=σ(S,Dt),k=1,2,…,l
(2)
式中:S为训练样本集;
σ为基学习算法。
②根据公式(3)分别计算l个分类器的加权误差率etk,取etk值最小的为最终弱分类器,记为ht(x),对应的误差率记为et。
(3)
式中:ωmi为第m轮迭代中第i个样本的权值。
③根据公式(4)计算弱分类器ht(x)在形成强分类器过程中所占的权重αt。
(4)
αt与et负相关,即在组合强分类器时,弱分类器的分类误差率越低其对应的权重越高。
④根据公式(5)更新训练集的样本权重分布。
(5)
(6)
式中:Zt是归一化因子,保证各样本权重之和为1。
3)生成强分类器。
经过T轮迭代后,通过式(7)将各个弱分类器加权线性组合生成最终的强分类器H(x),实现模型分类精度的提升。
(7)
1.2 代价敏感学习
实现代价敏感学习主要有3种方式[9]:从模型本身出发,改变算法结构使其适应非均衡数据集的学习及分类;
从贝叶斯风险理论出发,根据贝叶斯风险理论对分类结果进行处理;
从预处理出发,基于代价调整权重进而构造具有代价敏感特性的分类器。本文提出的Adacost模型属于第3类。
代价敏感学习的核心在于代价矩阵。代价矩阵用来描述待分类数据集上的代价(惩罚)信息,基于权重缩放法确定当不同分类错误导致不同惩罚力度时应如何训练分类器。多分类任务的代价矩阵示意图如图1所示。

图1 多分类任务的代价矩阵示意图Fig. 1 Schematic diagram of the cost matrix for multi-classification tasks
其中,矩阵元素cij表示将真实类别为i的样本错分到j类的代价;
矩阵的每行元素代表真实i类样本错分到其他各类别的代价;
当i=j时代表算法正确预测了样本类别。
1.3 结合AdaBoost和代价敏感的Adacost算法
在AdaBoost样本权重更新策略的基础上,引入代价敏感机制形成Adacost算法。相较于AdaBoost,Adacost主要改进在于其基于代价函数更新样本权重,对误分类且代价高的样本大大提高其权重,而对正确分类且代价高的样本适当降低其权重,使其权重降低的相对较小,即代价高的样本权重增加的快而降低的慢。这加强了对少数类样本的关注和学习,更好地考虑了少数类样本对整体分类准确率的影响,可以有效提升非均衡数据集下模型的少数类样本识别性能。其中样本分布的迭代公式更新如式(8)所示,Adacost算法原理如图2所示。

图2 Adacost算法原理Fig. 2 Principle of the Adacost algorithm
在公式(5)的基础上,引入惩罚因子βi得:
(8)
(9)
式中:Ci为第i个样本的分类代价,从代价矩阵中取值;
其中β+、β—分别表示样本被正确分类和错误分类情况下βi的取值。
2.1 特征参量选取
油中气体中各成分的含量及不同成分之间的比例关系与变压器运行状况密切相关,可为变压器故障诊断提供重要依据。油中不同气体含量差别很大,如果直接将气体含量作为模型输入参量,会导致模型性能不稳定,为此,国际电工委员会建议使用气体含量比值作为特征参量,常用的比值有IEC比值、Rogers比值、Dornenburg比值等[1],但上述比值数量偏少,无法充分表征出不同故障的差异,国内外学者在总结大量实验数据的基础上,进一步提出了无编码比值方法[13],相比传统比值方法具有更好的差异表征性能,故本文将其作为模型的输入特征参量,无编码比值具体如表1所示。

表1 气体比值特征Tab.1 Gas ratios features
2.2 设备状态编码
基于IEC 60599标准[14],同时考虑变压器故障类型主要分为放电和过热2种,本文划分变压器的运行状态为正常、低温过热、中温过热、高温过热、局部放电、低能放电以及高能放电7种类型。但实际上,大多数故障在发展过程中会同时发生放电与过热,因此增加放电兼过热为第8种运行状态。并在此基础上,分别对各运行状态进行编码得:0-正常,1-局部放电,2-低能放电,3-高能放电,4-低温过热,5-中温过热,6-高温过热,7-放电兼过热。
2.3 基学习器选择
考虑模型复杂度、适用范围及数据处理效率等因素,选择CART算法生成的决策树作为AdaBoost和Adacost分类模型的基学习器[15]。每个CART决策树的训练过程如图3所示。
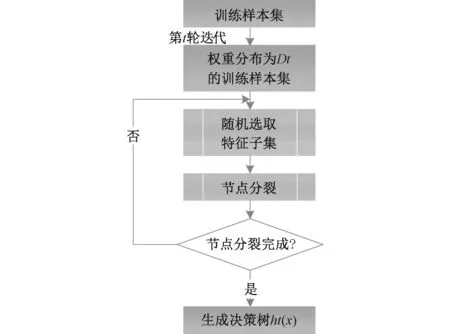
图3 AdaBoost和Adacost中单个决策树训练示意图Fig. 3 Training diagram of each DT in AdaBoost and Adacost models
CART决策树是一种二叉树,算法从根节点开始,用训练样本集递归建立CART分类树。生成决策树的重要步骤在于节点分裂,节点分裂完成的标志是节点中的样本个数小于预定阈值,或样本集的基尼系数小于预测阈值,即认为样本基本属于同一类。其中,基尼系数的定义如式(10)所示,假定给定数据集S有k个类别,第k个类别数量为Qk,数据集S的基尼系数为
(10)
2.4 代价矩阵确定
定义一个8阶方阵C,令方阵中的元素cij代表将变压器第i类运行状态误分类为第j类运行状态所带来的误诊断代价,则称方阵C为代价矩阵。代价矩阵C反映了变压器各运行状态之间的误诊断给工程现场所带来损失程度的相对差异。
在实际工程现场,将高危险等级的故障类型误判为低危险等级所带来的代价要远高于将低危险等级的故障类型误判为高危险等级。误诊断代价是一类独立于故障样本之外的领域先验知识,大多数文献中定义的代价矩阵均由专家结合领域知识综合打分给出[8-10],一定程度上保证了误诊断代价的合理性,但存在一定的不确定和主观性。因此,为保证代价矩阵的客观性,一些业内学者利用不同类别之间的样本数量比确定不同类别之间的误诊代价[16,17],样本数量越少意味着该类样本的误分类代价越高,但模型会存在局限性、过拟合等问题。
混淆矩阵又称为错误矩阵,是总结分析分类模型预测结果的情形分析表,具体形式如图4所示,与代价矩阵表征形式一致。考虑到混淆矩阵反映的是分类模型正确、错误分类的样本数,相较于样本数量比,其更能真实反映模型的分类偏好。因此本文根据模型的混淆矩阵初步确定代价矩阵,然后结合专家打分结果进行加权处理,最终确定代价矩阵。本文的初步代价矩阵由Adacost的对比模型-决策树的混淆矩阵确定。

图4 混淆矩阵示意图Fig. 4 Schematic diagram of a confusion matrix
2.5 基于Adacost算法的故障诊断流程
为解决电力变压器实际数据集所存在的类别非均衡问题,本文提出一种基于Adacost算法的设备智能故障诊断技术,其具体流程框架如图5所示。

图5 基于Adacost算法的故障诊断技术框架Fig. 5 Technical framework of fault diagnosis based on the Adacost algorithm
AdaBoost算法常用于二分类任务,而变压器故障诊断属于多分类任务,故本文采用一对一策略,针对变压器的8种运行状态分别构建28个二分类的Adacost模型,最后通过投票确定故障类型。
1)选取油中溶解气体无编码比值作为模型的输入特征参量,同时对样本运行状态进行编码。
2)采用分层抽样方法并按照3∶1的比例随机划分样本集得到类别分布一致的训练集和测试集。
3)使用决策树模型进行故障诊断,得到混淆矩阵,初步确定代价矩阵。
4)在初步代价矩阵的基础上,通过专家打分矩阵进行加权处理,确定Adacost模型的代价矩阵。
5)基于CART构建二分类Adacost模型,然后利用训练集对28个Adacost二分类器进行训练。
6)利用测试集对已训练好的28个Adacost二分类器进行诊断测试与应用。
7)对比分析决策树、AdaBoost及Adacost模型的故障诊断效果,并输出相应的评价指标。
3.1 数据获取及分布情况
本文采用的油浸式电力变压器油中溶解气体数据库来源于4处:变压器在线监测数据、变压器离线试验数据、变压器历史故障数据集和IEC TC 10数据库及相关权威出版物[18-20],前3项由国家电网公司提供,共覆盖了110~500 kV电压等级的变压器。该数据库包含1 342例样本,按照3∶1的比例随机划分得到训练样本1 009例和测试样本333例,样本分布情况如表2所示。数据集类别间样本数量比可以用来描述该数据集类别分布的不平衡程度。
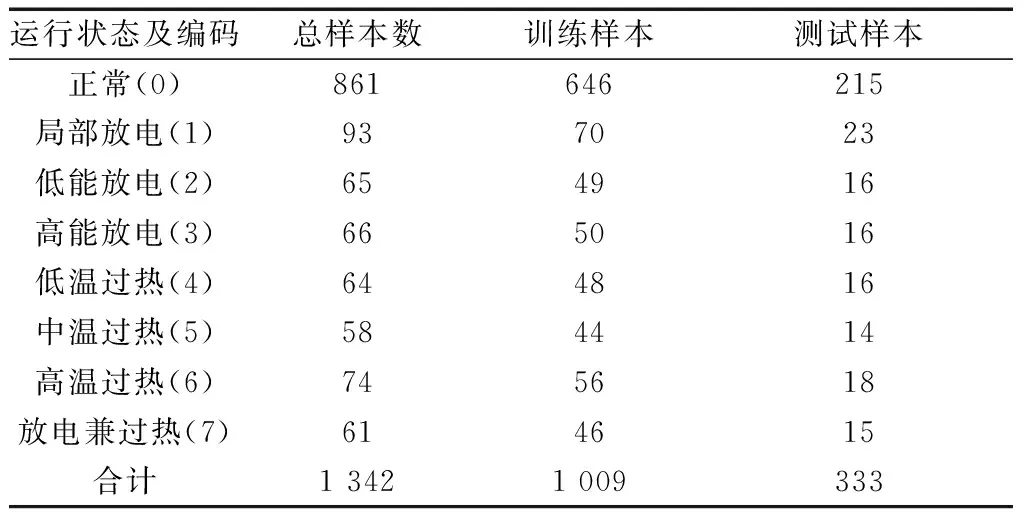
表2 样本数据具体分布Tab.2 Distribution of the samples
3.2 分类效果评价指标
变压器数据集中故障样本数量偏少,导致训练出的故障诊断模型容易发生漏判,漏判相比于误判具有更大的危害性,同时因为故障样本的比例太低,其对整体的分类准确率影响较小,因此对于样本类别分布非均衡的情况,不应仅以分类准确率评价模型性能,而应更加关注故障识别率。针对非均衡数据集的分类问题,本文基于混淆矩阵选用多分类评价指标体系来全面、有效地评估诊断模型的故障识别性能[21],其中混淆矩阵如图4所示。
由图4可知,数据集的总类别数为L,类别为i的样本被正确分类的数量为nii,其被误分为类别j的数量为nij。根据式(11)与式(12)定义类别i的查准率Pi和查全率Ri。
(11)
(12)
由式(11)与式(12)可知,查准率等价于诊断模型的分类准确度,即反映故障样本识别率的高低;
查全率等价于诊断模型的检索完整度,即反映故障样本漏判率的高低。综上所述,综合查准率和查全率可以充分反映诊断模型的综合分类性能。因此,本文选用了分类准确率、F1度量及G-mean构成诊断模型的评价指标体系,相应的计算公式分别如式(13)至式(15)所示。
(13)
(14)
(15)
3.3 结果分析与讨论
3.3.1 Adacost模型的代价矩阵设置
(1)决策树模型的混淆矩阵
基于划分好的训练集和测试集,使用决策树进行故障诊断,故障诊断情况分析表如图6所示。其中,黄色部分表示正确分类的样本数,颜色越深表示数量越多,绿色部分表示错误分类的样本数,颜色越浅表示数量越多。

图6 决策树模型的混淆矩阵可视化Fig. 6 Visualisation of the confusion matrix of the DT
(2)初步代价矩阵Cbase
错误分类的样本数越多,其惩罚权重应越大,使得分类器对其有足够的关注,从而降低少数类样本的漏判率,解决诊断模型对于多数类的分类偏好问题。因此基于图6,令诊断正确的代价为0,误诊断的代价为错误分类的样本数,得到初步的代价矩阵如表3所示。
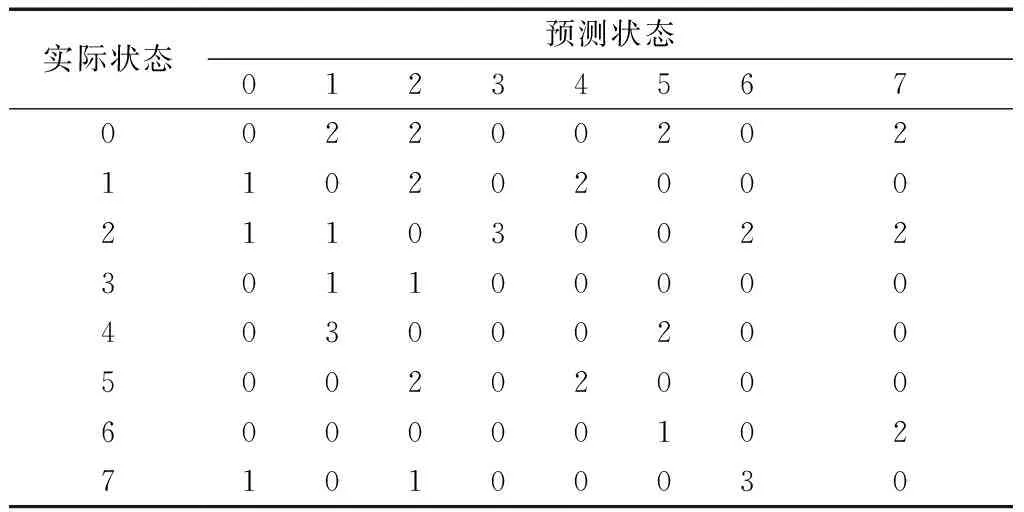
表3 故障误诊断的初步代价矩阵CbaseTab.3 Initial cost matrix Cbase for fault misdiagnosis
(3)专家打分矩阵Cweight
为了更加合理的确定变压器各运行状态之间的误诊断代价,需要专家综合领域知识给出打分情况。专家打分主要考虑两个层面,一是风险成本,即将高危险等级的故障类型误判为低危险等级所带来的成本,记为误诊损失程度,具体数值由专家打分给出,其中,依据电力导则、标准及故障报告等定义打分标准,具体如表4所示;
二是检修时间及人力成本,即将低危险等级的故障类型误判为高危险等级所带来的成本,记为检修代价,具体数值设为1,同时认为正确分类的代价为0。

表4 专家打分标准Tab.4 Standards for scoring by experts
基于上述原则,整理专家对表2中各类故障的误诊损失程度打分情况如表5所示。

表5 专家打分矩阵CweightTab.5 Matrix Cweight of scoring by experts
(4)Adacost的代价矩阵C
在初步代价矩阵Cbase的基础上,结合专家打分矩阵Cweight,通过加权公式(16)得到Adacost模型的代价矩阵C[8,22]。
C(i,j)=Cbase(i,j)Cweight(i,j)
(16)
式中:C(i,j)、Cbase(i,j)、Cweight(i,j)分别表示矩阵C、Cbase、Cweight中的i行j列元素。
考虑到代价权重过大容易引起模型过拟合问题,本文对数值大于5的C(i,j)元素进行折半处理,最终输入Adacost模型的代价矩阵C如图7所示。其中,无数字标识的表示不进行代价加权,颜色越深代表误判的代价越高。
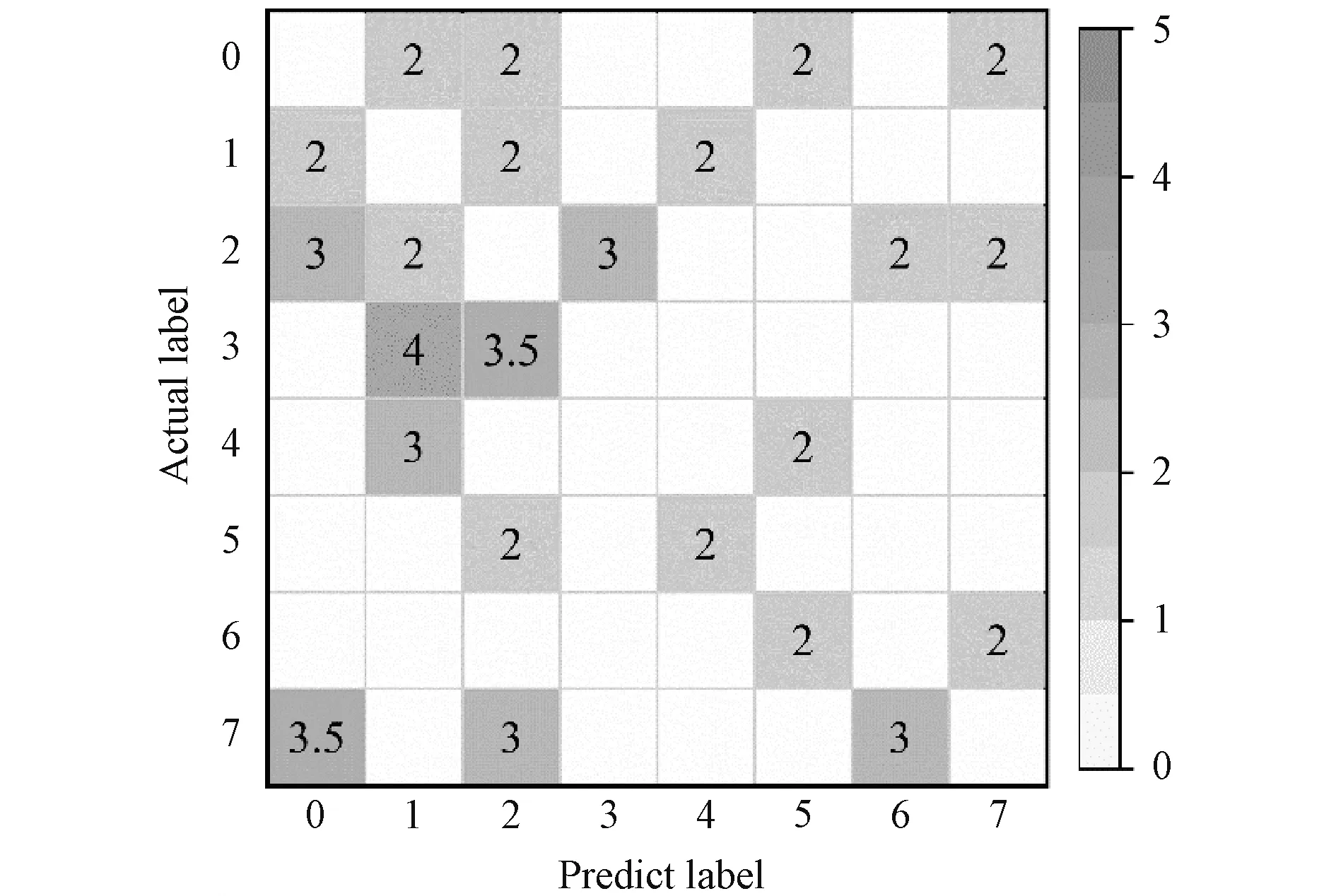
图7 Adacost模型的代价矩阵可视化Fig. 7 Visualisation of the cost matrix of the Adacost
3.3.2 Adacost模型的参数设置
构建多分类器通常有“一对一”和“一对多”两种策略,考虑到故障识别准确率,本文选择一对一策略构建故障诊断模型,即针对变压器的8种运行状态分别构建28个二分类的Adacost模型,最后通过投票确定故障类型。
本文采用CART算法生成的决策树作为Adacost分类模型的基学习器。CART通过基尼系数最小化准则选取最优特征,设置在每个节点上选择最佳随机拆分策略,其树的最大深度为1,拆分内部节点所需的最少样本数为2。考虑到基学习器数目对模型故障诊断及泛化性能等会产生一定影响,基学习器过多会增加模型的时间复杂度,甚至会降低模型的分类准确度。因此,本文通过进行多次参数试验,最终设定基学习器数目为48,同时选用了SAMME.R算法,使模型的收敛速度更快,并以更少的迭代次数实现更低的测试误差。
3.3.3 Adacost模型的可行性和有效性
以训练集为数据基础,分别对28个Adacost二分类器展开训练,并利用测试集验证代价敏感加权方法对于诊断模型故障识别性能的提升作用。同时,为进一步说明Adacost模型的可行性和有效性,本文选取决策树与AdaBoost 2种分类器进行对比分析。其中,决策树模型仍选用CART算法,并令树的最大深度为None,即认为将节点展开至所有叶子都是纯净的;
跟Adacost类似,Adaboost基学习器仍采用CART,其数目仍为48,考虑训练成本其树的最大深度仍为1。相较于深度为1的CART,深度为None的CART模型更为复杂,分类性能也更好,故本文选择深度为None的决策树作为对比模型来更为有效地说明Adacost性能的优越性。不同分类模型下的故障诊断结果如表6所示。

表6 不同分类模型下的故障诊断结果对比Tab.6 Comparison of fault diagnosis results using different models
由表6可知,相较于决策树和AdaBoost分类器,Adacost模型能够更为有效地提升分类器的故障识别性能。其中,决策树模型结合集成学习形成AdaBoost算法后,其λaccuracy、λF1、λG-mean指标较前者分别提高3.08%、10.87%和2.35%;
AdaBoost算法引入代价敏感矩阵形成Adacost模型后,其λaccuracy、λF1、λG-mean指标较前者分别提高4.65%、10.07%和16.86%;
决策树模型结合集成学习和代价敏感形成Adacost模型后,其λaccuracy、λF1、λG-mean指标较前者分别提高7.87%、22.03%和19.61%。因此,与传统故障诊断算法相比,本文提出的Adacost模型考虑了样本类别分布非均衡的现状,能够有效降低设备故障的漏判率,提升非均衡数据集下诊断模型的故障识别性能和整体分类性能。
针对非均衡数据集下电力变压器智能故障诊断模型对故障样本识别率低、漏判率高的问题,本文提出了一种结合AdaBoost和代价敏感的变压器故障诊断方法,并通过具体算例验证了该方法的可行性和有效性,得到如下结论:
(1)代价矩阵反映的是不同危险程度故障之间的误诊断代价。相较于主观专家经验、客观样本数量比等方法,专家打分和混淆矩阵结合的代价敏感矩阵既保证了矩阵的合理性和可信度,又保证了模型的客观性和泛化性。
(2)相较于决策树传统故障诊断算法,基于集成学习的AdaBoost和Adacost算法通过基学习器的级联提升基学习器的整体分类精度,有效增强了基学习器的故障识别能力。
(3)样本类别分布非均衡会导致AdaBoost算法的分类精度下降,对模型分类性能的提升较为有限。基于AdaBoost引入代价敏感机制的Adacost算法考虑了数据非均衡问题,能够有效降低设备故障的漏判率,提升非均衡数据集下诊断模型的故障识别性能和整体分类性能。
(4)本文提出的Adacost算法为电力设备智能状态评估的发展提供了一种新的思路,同时该算法并不局限于结构化数据,还可推广应用至半结构化数据及非结构化数据。后续将结合该算法,围绕电力变压器更多结构类型的监测信息展开研究。
猜你喜欢 决策树代价分类器 学贯中西(6):阐述ML分类器的工作流程电子产品世界(2022年4期)2022-04-21基于朴素Bayes组合的简易集成分类器①计算机系统应用(2021年2期)2021-02-23信息时代基于决策树对大学生情绪的分类数码世界(2020年4期)2020-06-18简述一种基于C4.5的随机决策树集成分类算法设计科学与信息化(2019年28期)2019-10-21一种自适应子融合集成多分类器方法计算机测量与控制(2019年4期)2019-05-08爱的代价海峡姐妹(2017年12期)2018-01-31幸灾乐祸的代价语文世界(初中版)(2017年5期)2017-06-22代价作文与考试·初中版(2017年12期)2017-04-19决策树学习的剪枝方法科学与财富(2016年32期)2017-03-04浅谈多分类器动态集成技术科技视界(2015年24期)2015-08-22栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: