自注意力环境下网络用户行为数据推荐方法
王 冲,赵艺璇,汪子尧
(桂林电子科技大学计算机与信息安全学院,广西 桂林 541004)
伴随信息时代的到来,网站日访问量剧增[1],用户间交流和上传行为包含多种类信息,极大影响了目标数据的检索效率和质量,降低使用者的满意度,门户网站存在巨大运营压力[2,3]。个性化数据推荐算法可根据用户的搜索、购买、评论等数据特征,给用户推荐符合自身需求的项目数据。
张祖平[4]等人在分析用户行为序列中相邻行为相似性和相关性的前提下,挖掘词语之间的结构耦合关系,输出深度学习下用户行为推荐结果,但该方法计算步骤繁琐,数据推荐准确率较低;
贾俊杰[5]等人从社区中用户-项目评分数据得到可信度与隐含信任值,凭借用户推荐能力提取专家数据集,融合用户不同评分标准完成推荐项目预测。但创建数据集时仅考虑了集合内的强关系,数据集缺乏多样性与完整性,造成了数据推荐内容覆盖范围较小的问题。
本文提出一种基于自注意力机制的网络用户行为数据推荐方法。利用自注意力机制构建用户行为偏好模型,增强人类视觉处理信息的速率与准确性,运用区间型符号方法计算用户行为的相似度权重,预测用户行为数据评分,将评分最高的项目作为推荐信息完成网络推送。最终通过仿真对比,验证了所提方法数据推荐的可行性,能够给用户提供更加优质的检索服务。
用户偏好是不断变化的,当用户关注某些内容时,就会忽略其它内容,故本文引入自注意力机制构建来用户行为偏好模型,分析用户行为数据之间的内在关联,获得更加准确的用户行为偏好方向,提升数据推荐准确性。
偏好模型有两部分:一是用来学习用户潜在偏好的集合Su,集合内包含行为特征数据嵌入,特征提取、自注意力建模、潜在学习四个阶段;
二是使用多层全连接神经网络组成的行为特征集合Sv。
不同的用户行为都具备相应的特征,在导入行为特征信息时,串联各个行为特点,编码为一个固定长度的二进制数量[6],将其作为模型输入值。以单人用户为例,用户交互行为导入完毕后,将用户交互行为的特征矢量记作I=(I1,…,It)。
提取行为特征时,使用全连接神经网络,把用户的交互行为映射至一维空间,映射过程为
Id=fRelu(WI+b)
(1)
式中,Id是d维空间中用户i的交互行为特征,fRelu(·)代表激活函数,是Relu的单层全连接神经网络。
自注意力建模,就是在行为特征从d维空间向z维空间映射时,导入自注意力理念、梳理网络用户行为耦合关系的过程,自注意力策略原理为
lz=fRelu(WId+b)
(2)
A=softmax(IzW(Id)T)
(3)
Iz=AIz
(4)
式中,W表示权重矩阵,b是偏置。式(2)是把d维空间的网络用户交互行为特征映射至一维空间。利用式(3)可获得d维空间中的全部用户交互行为对一维空间各用户交互行为的贡献权重,使用softmax函数归一化后的矩阵A就是每个行为之间的注意力权重。式(4)使用自注意力权证矩阵A对z维空间中的行为实施加权运算,获得的输出结果Iz是最终的网络用户行为特征,下面统一使用fself(·)描述自注意力的运算过程。
为了更好地展现用户行为之间的内涵联系,使用三次独立[7]下的自注意力机制完成行为建模,计算公式为

(5)

潜在学习是串联三次注意力机制加权后的行为表现[8],将其当作网络输入,获得网络用户行为的潜在特点,详细过程为
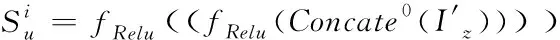
(6)

将模型的行为特征集合记作
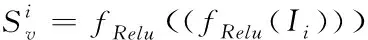
(7)
式中,Ii代表网络行为特征数据引入模型后的二进制矢量。
自注意力模型训练过程的输入值是用户交互行为集合与用户偏好行为,衡量用户行为偏好和行为特征之间的相似性。将模型函数表达式描述成

(8)
利用上述计算过程即可明确用户网络浏览或搜索行为的兴趣偏好,为接下来区间型符号下网络用户行为数据推荐方法提供良好的运算基础条件。符号数据分析是一种探究怎样在大量数据内发现系统知识理论的策略,使用“数据打包”思想,不但完成大规模样本空间降维,还能掌握样本特征,揭示隐藏在数据内部的规律[9,10],将打包后的样本称作符号目标,样本从初始的“点数据”变换成“符号数据”。
如果随机变量X服从某个任意分布,同时该变量的观测值处于[a,b]的取值范围内,把X称作一般分布的区间型符号变量,简称为区间变量;
[a,b]是区间型符号数据,即区间数。在计算用户行为类型方面本文将改进传统Hausdorff距离算法,设计区间型数据的新距离计算方法。假设A=[a,b]与B=[c,d]是两个区间数,将其看作两个紧集[11],那么A、B之间的Hausdorff距离是
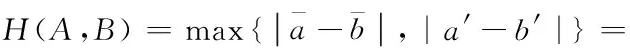
|c(A)-c(B)|+|r(A)-r(B)|
(9)
式中,c(X)是区间数X的中点,r(X)是区间数X的半径,这里X=A或B。由此看出,若两个区间数变为两个实数,则式(9)就是两个实数的绝对值距离。
设定A、B是两个随机区间数,且数值内部的点数据已知,则A、B之间的符号距离为

(10)
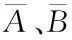
在获取一般分布区间型符号数据距离值的前提下,将用户拟作一个群组,用户的网络行为当作操作项目,拓展传统K均值聚类方法,引入网络用户行为数据推荐。方法包含三个步骤:使用区间型符号数据定义用户对项目的评分;
明确目标群组的最近邻;
预测目标群组评分并完成数据推荐。
设群组k内的个体评分项目为m,倘若个体i对项目m的评分最低分数是ak,m,个体j对项目m的评分最高分数是bk,m,获得群组k对项目m评分的区间型符号数据为
xk,m=[ak,m,bk,m]
(11)
如果总群组R内共包含N个群组,总群组对项目m的评分区间型符号数据为
X=(x1,m,x2,m,…,xN,m)
=([a1,m,b1,m],[a2,m,b2,m],…,[aN,m,bN,m])
(12)
将N个群组对项目总数M的符号数据矩阵描述成

(13)
将群组之间的距离当作挑选目标群组的最近邻[12],群组的间距越小,相似性越高。推算群组间距时,随机挑选某个项目m,根据K均值聚类方法获得目标群组k针对项目m的相似群组数据集Pm,以此类推即可得到目标群组k对各项目的相似群组数据集,构成集合{Pm}。若群组c处于相似群集合内,计算群组c与目标群组k的间距


(14)
式中,Xk,m、Xc,m依次代表群组k、c中用户对项目m评分均值,Sk,m、Sc,m依次是群组k、c中用户对项目m评分的标准差。
把相似群集合内和目标群组间距最短的前n个群组当作群组k的最近邻,如果群组c处于最近邻NK中,按照距离越短相似性越高的定理,将群组c与群组k的相似度权重解析式记作

(15)
式中,D(k,i)为两个群组间距的临界值。
为用户进行相关的数据推荐首先要预测目标群组对项目的评分,预测公式为

(16)
式中,wc是两个群组的相似度权重,gc,m是群组c关于项目m的评分等级,pk是群组k最近邻构成的数据集。
拓展群组评分等级gc,m,记作

(17)
式中,nc是群组c对用户行为数据评价的个体数量,qc,m(i)是用户行为数据的评分。
选取预测评分ρ(k,m)最高的前N个项目,将其看作最优的数据推荐信息进行网络推送,实现网络用户行为数据推荐任务。
4.1 数据集与评估指标
为评估本文数据推荐方法的可靠性,对其进行仿真,将文献[4]深度学习法与文献[5]融合偏置法作为对比方法,实验平台为Simulink。在充分考虑用户个人隐私的基础上,从Twitter数据集获取实验信息,表1是数据集的基础内容。Twitter数据集的评分范围是1~5,涵盖48962个用户和136597个项目,实验从Twitter数据集内随机挑选8000个用户和18500个项目作为本次实验的数据集。
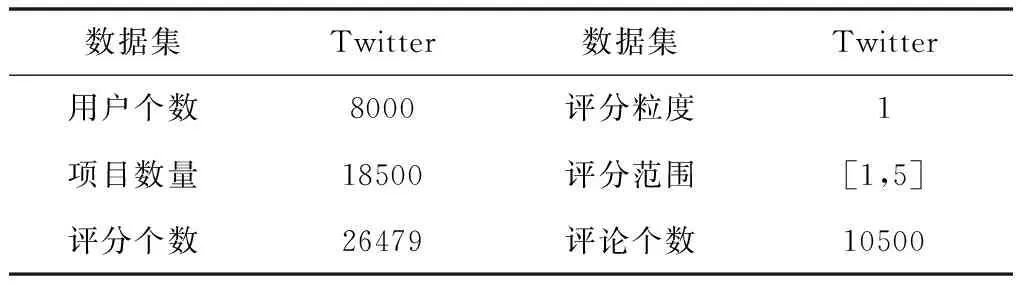
表1 Twitter数据集基础内容
使用平均绝对误差(Mean Absolute Error,MAE)指标分析三种方法数据推荐精准度,针对一个涵盖O个评分的数据集,平均绝对误差推导过程为

(18)
式中,rp表示目标项目的预测分数,ri是项目的真实分数。平均绝对误差值越小,表明数据推荐精准度越高。
为验证数据推荐内容的全面性,让用户获得更加舒心的服务体验,设计推荐覆盖率评估指标,指标计算公式为:

(19)
式中,E为预测评分的个数,|Ω|是数据集中的总评分量。覆盖率数值越大,表明数据推荐的覆盖性能越优,用户得到自身偏好信息的概率越高。
F1是统计学用于评价模型正确性的指标,同时兼顾算法精确率与召回率,用F1指标估计推荐算法的整体性能优劣
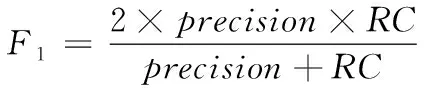
(20)
式中,precision表示精准度。
4.2 实验结果分析
将推荐列表长度作为实验目标,选取前4个项目推荐给用户。

图1 三种方法平均绝对误差值指标对比
图1为三种方法的数据推荐平均绝对误差值对比示意图,观察实验结果可知,随着推荐列表长度的增加,本文方法与深度学习法、融合偏置法相比,平均绝对误差值的上下浮动最小,误差值最低,达到了现实场景下期望的数据推荐精度标准。因为本文方法采用自注意力机制创建用户行为偏好模型,展现海量用户行为数据背后的隐含关联,获悉用户网络浏览与搜索行为偏好,大幅增强数据推荐算法实用性。
三种方法数据推荐覆盖率情况如图2所示。

图2 三种方法推荐覆盖率对比
可以看到,本文方法针对大规模数据集的推荐覆盖率要远远优于两个对比方法,在推荐内容全面性方面具有显著优势。由于本文方法引入“数据打包”概念,使用区间型符号算法实现样本空间降维,有效保证了数据的完整性。而深度学习法与融合偏置法在数据预处理阶段为提升运算速率,剔除了很多数据集有用信息,所以推荐覆盖率较低。
图3为三种方法的F1值对比结果。

图3 三种方法F1值对比
从图3看出,本其它两种文献方法的F1均不同程度地小于本文方法,证明在精确率与召回率方面,所提方法依旧具备独特优势。原因在于,本文方法消除数据集冗余数据的同时,保存了网络的强弱关联数据,增强了数据推荐全局可靠性。
数据推荐算法是数据挖掘的重要分支之一,被大量运用于各大电商平台及社交软件中。为了节约用户检索时间并增强用户体验感,设计一种自注意力机制下网络用户行为数据推荐方法。本文充分改进传统深度学习方法不足,通过构建自注意力偏好模型来完善数据推荐的精准度,得到令人满意的推荐结果。但伴随用户与商品信息的激增,方法的训练时间与运算复杂度也随之提升,在今后的工作中会使用并行计算提高方法的计算效率。
猜你喜欢 群组区间注意力 你学会“区间测速”了吗中学生数理化·八年级物理人教版(2022年9期)2022-10-24让注意力“飞”回来小雪花·成长指南(2022年1期)2022-04-09全球经济将继续处于低速增长区间中国外汇(2019年13期)2019-10-10Boids算法在Unity3D开发平台中模拟生物群组行为中的应用研究网络安全技术与应用(2019年5期)2019-06-05“扬眼”APP:让注意力“变现”传媒评论(2017年3期)2017-06-13A Beautiful Way Of Looking At Things第二课堂(课外活动版)(2016年2期)2016-10-21区间对象族的可镇定性分析北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27群组聊天业务在IMS客户端的设计与实现计算机工程与设计(2011年7期)2011-09-07单调区间能否求“并”中学理科·综合版(2008年9期)2008-10-15栏目最新:
- 2024年度在理论学习中心组关于群众路线...2024-01-16
- 在退役军人事务工作领导小组会议上讲话...2024-01-15
- 中秋国庆队伍教育管理工作动员部署会议...2024-01-15
- 2024年度区委书记在文旅农康融合发展大...2024-01-14
- 医院纪检监察干部队伍教育整顿个人党性...2024-01-14
- 教师演讲稿:牢记育人使命,涵养高尚师德...2024-01-13
- 2024年组织部长在市委理论学习中心组专...2024-01-13
- 2024年区人民法院案件质量评查办法(2篇...2024-01-13
- 2024年区长在指导某街道干部作风建设动...2024-01-11
- 在公司成立周年大会上讲话(3篇)(完整...2024-01-10
相关文章: